RDFLib를 사용해 데이터세트의 메타데이터를 DCAT으로 표현하기 1️⃣
2022. 09. 02. 20:00 by 박하람
이 포스트는 시리즈물로, 다음 편 RDFLib를 사용해 데이터세트의 메타데이터를 DCAT으로 표현하기 2️⃣ 으로 이어집니다. 사용한 데이터와 전체 코드는 깃헙 레포에서 공개하고 있습니다.
👀 전체 코드보기: rdflib-tutorial
본인은 데이터가 가벼운 경우 OpenRefine으로 변환하고, 데이터의 양이 큰 경우 RDFLib로 변환하고 있다. 특히, 건축물대장과 같이 2G가 넘어가는 데이터는 OpenRefine 보다 RDFLib로 변환하는 것이 편하다. 데이터 전처리는 Pandas로 하고, 데이터 변환은 RDFLib로 하면 된다. 오늘의 튜토리얼은 RDFLib를 사용하여 공공데이터포털의 개방목록현황(8월)을 DCAT으로 표현하는 것이 목적이다.
모듈 설치하기
설치된 RDFLIb의 버전은 6.2.0이다.
!pip install rdflib
데이터 불러오기
DCAT은 데이터세트의 메타데이터를 표현하는 어휘이다. 데이터는 공공데이터포털(data.go.kr)의 개방목록현황(8월)을 변환에 사용한다.
import numpy as np
import pandas as pd
data = pd.read_csv("data/개방목록현황_8월.csv", encoding="utf-8", dtype=str)
data = data.replace({np.nan : None})
data.head()
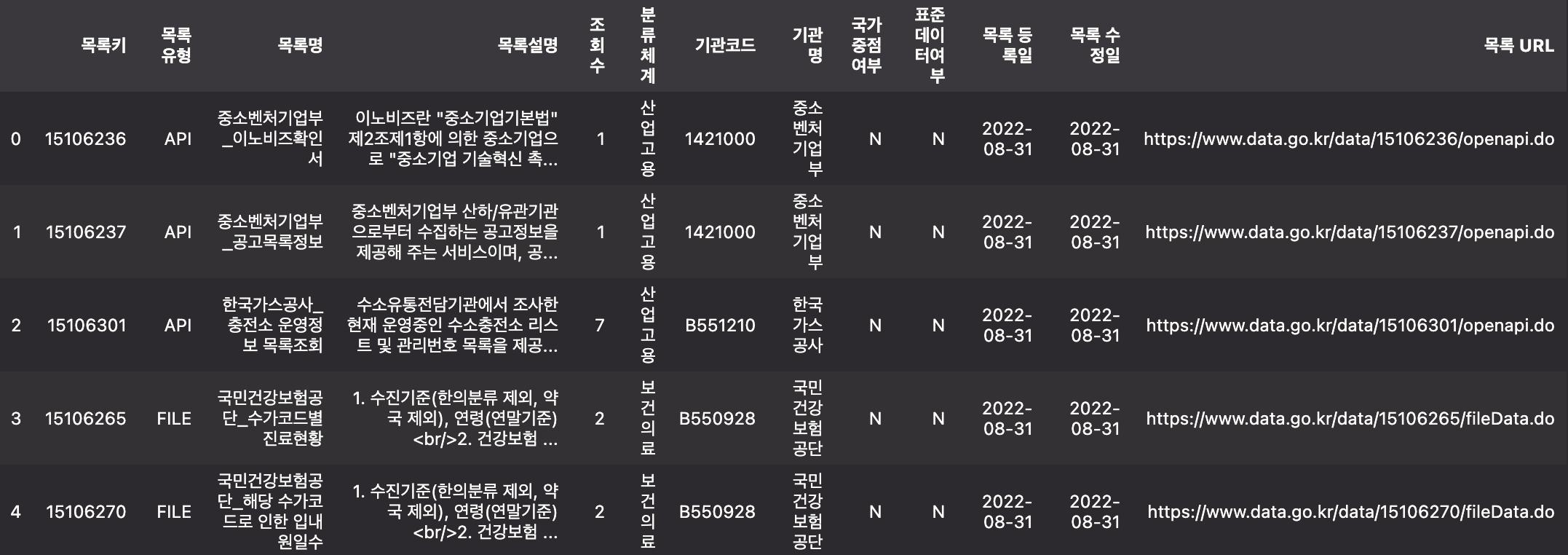
데이터 파악하기
개방목록현황은 공공데이터포털에서 표현되는 모든 메타데이터가 표현되지 않는다. 또한 DCAT으로 표현할 수 없는 메타데이터도 존재한다. 데이터를 살펴보며 변환이 가능한 메타데이터 항목과 최소한의 전처리를 진행한다.
print(f"데이터의 행과 열은 {data.shape}입니다.")
print(f"데이터의 컬럼명은 {data.columns}입니다.")
# results
데이터의 행과 열은 (63468, 13)입니다.
데이터의 컬럼명은 Index(['목록키', '목록유형', '목록명', '목록설명', '조회수',
'분류체계', '기관코드', '기관명', '국가중점여부',
'표준데이터여부', '목록 등록일', '목록 수정일', '목록 URL'],
dtype='object')입니다.
8월 기준 공공데이터포털에서 개방하는 데이터세트는 약 6만건이다. 제공하는 메타데이터 개수는 13개다. 한편, DCAT으로 표현되는 데이터세트는 데이터세트별로 고유한 URI값을 가져야 한다. 보통은 메타데이터 중 개별 데이터세트를 관리하는 식별자를 사용하는 것이 좋다. 현재 데이터는 '목록키'가 고유한 값으로 보이니 확인해보자.
# results
print(f"고유한 목록키의 개수는 {len(data['목록키'].unique())}개입니다.")
고유한 목록키의 개수는 63468개입니다.
전체 행이 63,468개이고, 고유한 목록키의 개수도 63,468개이므로 URI의 ID 값으로 목록키를 사용할 수 있다.
DCAT은 데이터세트를 표현하는 클래스(dcat:Dataset)와 카탈로그를 표현하는 클래스(dcat:Catalog), API와 같은 데이터 서비스를 표현하는 클래스(dcat:DataService)가 존재한다. 사람마다 카탈로그를 바라보는 기준은 다를 수 있지만, 본 글은 카탈로그를 여러 개의 데이터세트와 데이터 서비스를 담을 수 있는 집합으로 표현한다.1
카탈로그는 공공데이터포털이라는 데이터포털 자체를 카탈로그로 볼 수 있고, 표준데이터나 국가중점데이터와 같이 특별한 주제의 데이터세트의 집합도 카탈로그라고 볼 수 있다. 본 글은 표준데이터와 국가중점데이터를 카탈로그로 표현한다. 다음은 전체 데이터세트 중 국가중점데이터와 표준데이터에 포함된 개수다.
data.groupby(["국가중점여부"])['목록키'].count()
# results
국가중점여부
N 60621
Y 2847
Name: 목록키, dtype: int64
data.groupby(["표준데이터여부"])["목록키"].count()
# results
표준데이터여부
N 63321
Y 147
Name: 목록키, dtype: int64
국가중점데이터 카탈로그는 2,847개의 데이터세트를 포함하고, 표준데이터 카탈로그는 147개의 데이터세트를 포함할 것이다.
컬럼명 중 '목록유형', '조회수', '분류체계'는 적절한 DCAT 어휘가 존재하지 않는다.2 필요 없는 컬럼은 삭제한다.
data = data.drop(["목록유형", "조회수", "분류체계"], axis=1)
마지막으로 변환을 위해 최소한의 전처리만 수행한다. 간단하게 모든 값의 앞뒤 공백만 지운다.
data[data.columns] = data.apply(lambda x: x.str.strip())
데이터 변환을 위한 준비
변환에 사용할 함수 만들기
가장 먼저 변환에 사용할 RDFLib 함수를 불러온다. 첫번째 줄은 URI 생성에 필요한 함수를 불러온 것이다. 두번째 줄은 RDF 데이터를 담을 객체 Graph를 가져온다. 세번째 줄은 RDFLib에 내장된 네임스페이스를 불러온다. 불러온 네임스페이스 중 DCAT, DCTERMS, RDF, RDFS, XSD를 사용한다.
# URI 생성에 필요한 함수 불러오기
from rdflib import Namespace, Literal, URIRef
# 데이터 변환 후 담을 저장소
from rdflib.graph import Graph, ConjunctiveGraph
# 미리 rdflib에 내장된 네임스페이스 불러오기
from rdflib.namespace import CSVW, DC, DCAT, DCTERMS, DOAP, FOAF, ODRL2, ORG, OWL, \
PROF, PROV, RDF, RDFS, SDO, SH, SKOS, SOSA, SSN, TIME, \
VOID, XMLNS, XSD
변환은 크게 2가지로 구분된다. 목적어가 (1) Literal로 표현되는 값과 (2) URI로 표현되는 값이다. 아래와 같이 2종류의 함수를 생성한다3. 첫번째 cell 함수는 값이 None이 아닐 때 목적어가 Literal로 표현된다. lang에서 언어 태그를 붙여줄 수 있다. 두번째 uri 함수는 값이 None이 아닐 때 목적어가 URI로 표현된다. objClass는 어떤 유형으로 변환되는지 지정하고, objURI는 목적어의 URI 경로를 설정한다.
# function (convert data to rdf)
def cell(store, s, p, df_col, datatype = None, lang = None):
if df_col != None:
store.add((s, p, Literal(df_col, datatype=datatype, lang = lang)))
def uri(store, s, p, df_col, objClass = None, objURI = None) :
if df_col != None :
obj = URIRef(objURI + df_col)
store.add((s, p, obj))
if objClass != None :
store.add((obj, RDF.type, objClass))
한편, 데이터세트의 기관에 대한 표현은 KOOR 어휘를 사용한다. RDFLib에 내장되지 않은 네임스페이스를 사용할 경우, 아래와 같이 정의한다. 마지막으로 DCAT으로 표현될 자원의 URI 경로를 정의한다.
# namespace
koor_def = "http://vocab.datahub.kr/def/organization/"
koor_id = "http://data.datahub.kr/id/organization/"
KOOR = Namespace(koor_def)
dcat_id = "http://data.datahub.kr/id/dcat/"
지금까지 데이터 변환을 위한 작업 과정을 간단하게 살펴보았다. 다음 포스트에서 본격적으로 RDFLib로 데이터 변환 작업을 설명한다.
이 포스트는 시리즈물로, 다음 편 RDFLib를 사용해 데이터세트의 메타데이터를 DCAT으로 표현하기 2️⃣ 으로 이어집니다. 사용한 데이터와 전체 코드는 깃헙 레포에서 공개하고 있습니다.
👀 전체 코드보기: rdflib-tutorial
본인은 데이터가 가벼운 경우 OpenRefine으로 변환하고, 데이터의 양이 큰 경우 RDFLib로 변환하고 있다. 특히, 건축물대장과 같이 2G가 넘어가는 데이터는 OpenRefine 보다 RDFLib로 변환하는 것이 편하다. 데이터 전처리는 Pandas로 하고, 데이터 변환은 RDFLib로 하면 된다. 오늘의 튜토리얼은 RDFLib를 사용하여 공공데이터포털의 개방목록현황(8월)을 DCAT으로 표현하는 것이 목적이다.
모듈 설치하기
설치된 RDFLIb의 버전은 6.2.0이다.
!pip install rdflib
데이터 불러오기
DCAT은 데이터세트의 메타데이터를 표현하는 어휘이다. 데이터는 공공데이터포털(data.go.kr)의 개방목록현황(8월)을 변환에 사용한다.
import numpy as np
import pandas as pd
data = pd.read_csv("data/개방목록현황_8월.csv", encoding="utf-8", dtype=str)
data = data.replace({np.nan : None})
data.head()
데이터 파악하기
개방목록현황은 공공데이터포털에서 표현되는 모든 메타데이터가 표현되지 않는다. 또한 DCAT으로 표현할 수 없는 메타데이터도 존재한다. 데이터를 살펴보며 변환이 가능한 메타데이터 항목과 최소한의 전처리를 진행한다.
print(f"데이터의 행과 열은 {data.shape}입니다.")
print(f"데이터의 컬럼명은 {data.columns}입니다.")
# results
데이터의 행과 열은 (63468, 13)입니다.
데이터의 컬럼명은 Index(['목록키', '목록유형', '목록명', '목록설명', '조회수',
'분류체계', '기관코드', '기관명', '국가중점여부',
'표준데이터여부', '목록 등록일', '목록 수정일', '목록 URL'],
dtype='object')입니다.
8월 기준 공공데이터포털에서 개방하는 데이터세트는 약 6만건이다. 제공하는 메타데이터 개수는 13개다. 한편, DCAT으로 표현되는 데이터세트는 데이터세트별로 고유한 URI값을 가져야 한다. 보통은 메타데이터 중 개별 데이터세트를 관리하는 식별자를 사용하는 것이 좋다. 현재 데이터는 '목록키'가 고유한 값으로 보이니 확인해보자.
# results
print(f"고유한 목록키의 개수는 {len(data['목록키'].unique())}개입니다.")
고유한 목록키의 개수는 63468개입니다.
전체 행이 63,468개이고, 고유한 목록키의 개수도 63,468개이므로 URI의 ID 값으로 목록키를 사용할 수 있다.
DCAT은 데이터세트를 표현하는 클래스(dcat:Dataset)와 카탈로그를 표현하는 클래스(dcat:Catalog), API와 같은 데이터 서비스를 표현하는 클래스(dcat:DataService)가 존재한다. 사람마다 카탈로그를 바라보는 기준은 다를 수 있지만, 본 글은 카탈로그를 여러 개의 데이터세트와 데이터 서비스를 담을 수 있는 집합으로 표현한다.1
카탈로그는 공공데이터포털이라는 데이터포털 자체를 카탈로그로 볼 수 있고, 표준데이터나 국가중점데이터와 같이 특별한 주제의 데이터세트의 집합도 카탈로그라고 볼 수 있다. 본 글은 표준데이터와 국가중점데이터를 카탈로그로 표현한다. 다음은 전체 데이터세트 중 국가중점데이터와 표준데이터에 포함된 개수다.
data.groupby(["국가중점여부"])['목록키'].count()
# results
국가중점여부
N 60621
Y 2847
Name: 목록키, dtype: int64
data.groupby(["표준데이터여부"])["목록키"].count()
# results
표준데이터여부
N 63321
Y 147
Name: 목록키, dtype: int64
국가중점데이터 카탈로그는 2,847개의 데이터세트를 포함하고, 표준데이터 카탈로그는 147개의 데이터세트를 포함할 것이다.
컬럼명 중 '목록유형', '조회수', '분류체계'는 적절한 DCAT 어휘가 존재하지 않는다.2 필요 없는 컬럼은 삭제한다.
data = data.drop(["목록유형", "조회수", "분류체계"], axis=1)
마지막으로 변환을 위해 최소한의 전처리만 수행한다. 간단하게 모든 값의 앞뒤 공백만 지운다.
data[data.columns] = data.apply(lambda x: x.str.strip())
데이터 변환을 위한 준비
변환에 사용할 함수 만들기
가장 먼저 변환에 사용할 RDFLib 함수를 불러온다. 첫번째 줄은 URI 생성에 필요한 함수를 불러온 것이다. 두번째 줄은 RDF 데이터를 담을 객체 Graph를 가져온다. 세번째 줄은 RDFLib에 내장된 네임스페이스를 불러온다. 불러온 네임스페이스 중 DCAT, DCTERMS, RDF, RDFS, XSD를 사용한다.
# URI 생성에 필요한 함수 불러오기
from rdflib import Namespace, Literal, URIRef
# 데이터 변환 후 담을 저장소
from rdflib.graph import Graph, ConjunctiveGraph
# 미리 rdflib에 내장된 네임스페이스 불러오기
from rdflib.namespace import CSVW, DC, DCAT, DCTERMS, DOAP, FOAF, ODRL2, ORG, OWL, \
PROF, PROV, RDF, RDFS, SDO, SH, SKOS, SOSA, SSN, TIME, \
VOID, XMLNS, XSD
변환은 크게 2가지로 구분된다. 목적어가 (1) Literal로 표현되는 값과 (2) URI로 표현되는 값이다. 아래와 같이 2종류의 함수를 생성한다3. 첫번째 cell 함수는 값이 None이 아닐 때 목적어가 Literal로 표현된다. lang에서 언어 태그를 붙여줄 수 있다. 두번째 uri 함수는 값이 None이 아닐 때 목적어가 URI로 표현된다. objClass는 어떤 유형으로 변환되는지 지정하고, objURI는 목적어의 URI 경로를 설정한다.
# function (convert data to rdf)
def cell(store, s, p, df_col, datatype = None, lang = None):
if df_col != None:
store.add((s, p, Literal(df_col, datatype=datatype, lang = lang)))
def uri(store, s, p, df_col, objClass = None, objURI = None) :
if df_col != None :
obj = URIRef(objURI + df_col)
store.add((s, p, obj))
if objClass != None :
store.add((obj, RDF.type, objClass))
한편, 데이터세트의 기관에 대한 표현은 KOOR 어휘를 사용한다. RDFLib에 내장되지 않은 네임스페이스를 사용할 경우, 아래와 같이 정의한다. 마지막으로 DCAT으로 표현될 자원의 URI 경로를 정의한다.
# namespace
koor_def = "http://vocab.datahub.kr/def/organization/"
koor_id = "http://data.datahub.kr/id/organization/"
KOOR = Namespace(koor_def)
dcat_id = "http://data.datahub.kr/id/dcat/"
지금까지 데이터 변환을 위한 작업 과정을 간단하게 살펴보았다. 다음 포스트에서 본격적으로 RDFLib로 데이터 변환 작업을 설명한다.