Streamlit으로 데이터 분석 결과를 빠르게 시각화하기
2024. 04. 29. by 박하람
학부 수업 시간에 Streamlit 튜토리얼 강의를 진행했다. 간단하게 streamlit을 사용할 수 있는 방법을 중심으로 강의를 진행했다. streamlit을 실행하는 프로젝트 환경 구축부터 실제 데이터로 웹 페이지에 분석할 수 있는 방법까지 소개한다. 전체 소스코드는 깃헙의 streamlit-tutorial 레포에서 공개하고 있다.
프로젝트 환경 구축하기
streamlit는 다양한 모듈을 사용하고 있어 설치에 꽤나 애를 먹는다. 기본적으로 venv를 사용해 가상환경에서 streamlit을 실행할 수 있는 환경을 설정해주는 것이 좋다. streamlit-tutorial의 레포를 가져온 다음, 다음과 같이 설정하면 streamlit을 위한 가상환경을 생성할 수 있다. git clone 후에 streamlit-tutorial의 가장 상단의 경로에서 가상환경을 실행해야 한다는 것을 잊지말자.
# 1. git clone
git clone https://github.com/givemetarte/streamlit-tutorial.git
# 2. generate python bubble
python -m venv env
# 3. activate
source env/bin/activate # mac
env\Scripts\activate.bat # window
# 4. install dependencies
pip install -r requirements.txt
# 5. run streamlit
streamlit run main.py
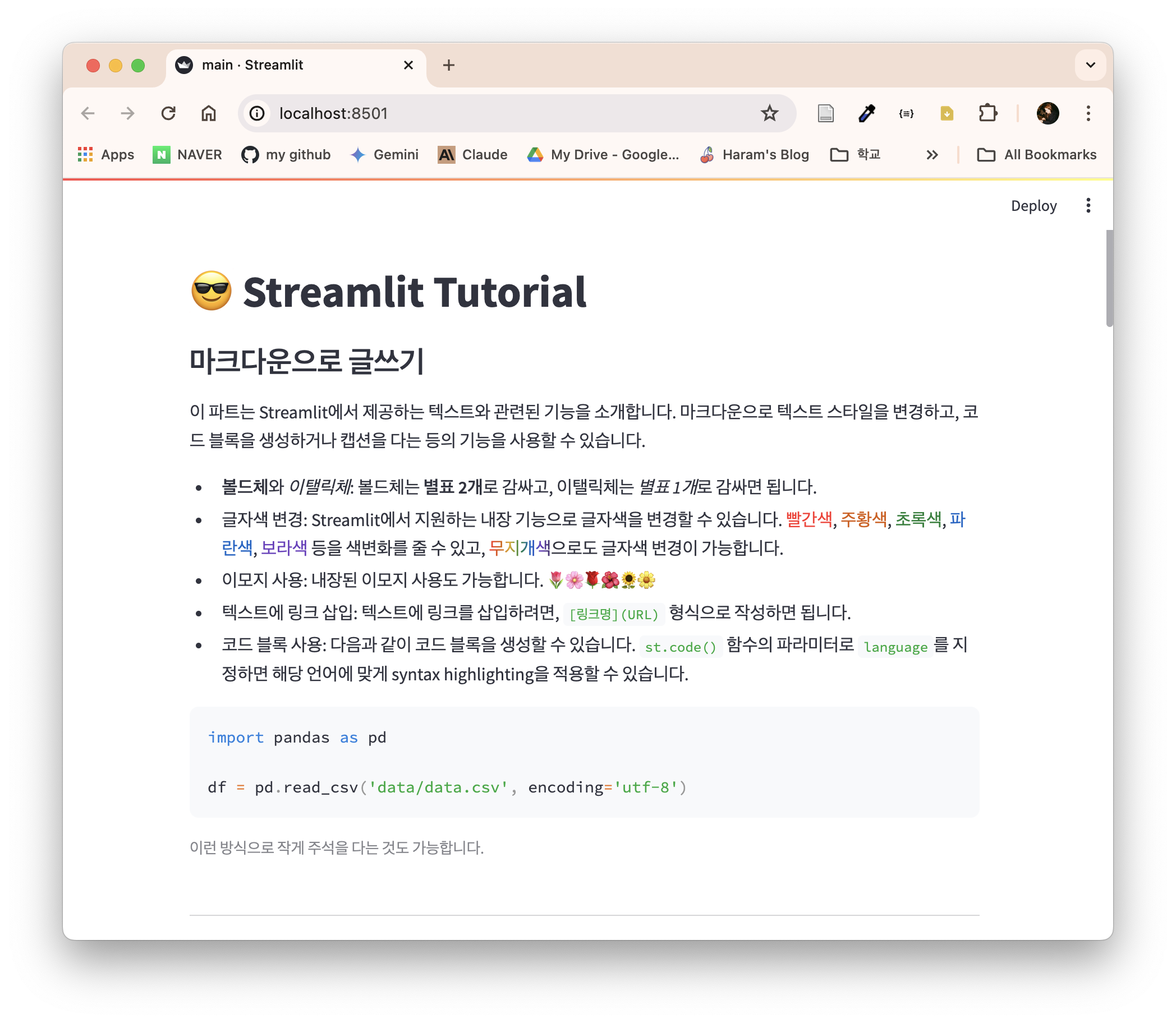
localhost:8501에서 다음과 같은 화면이 나타나면 streamlit이 무사히 실행된 것이다.
데이터 분석과 시각화
데이터 분석은 공공데이터포털의 전국도서관표준데이터를 활용한다. 이 데이터로 (1) 소장자료수(도서)를 가장 많이 제공하는 상위 5개의 도서관을 출력하고, 92) 시도별 도서관의 소장자료수(도서)를 분석한다.
st.dataframe
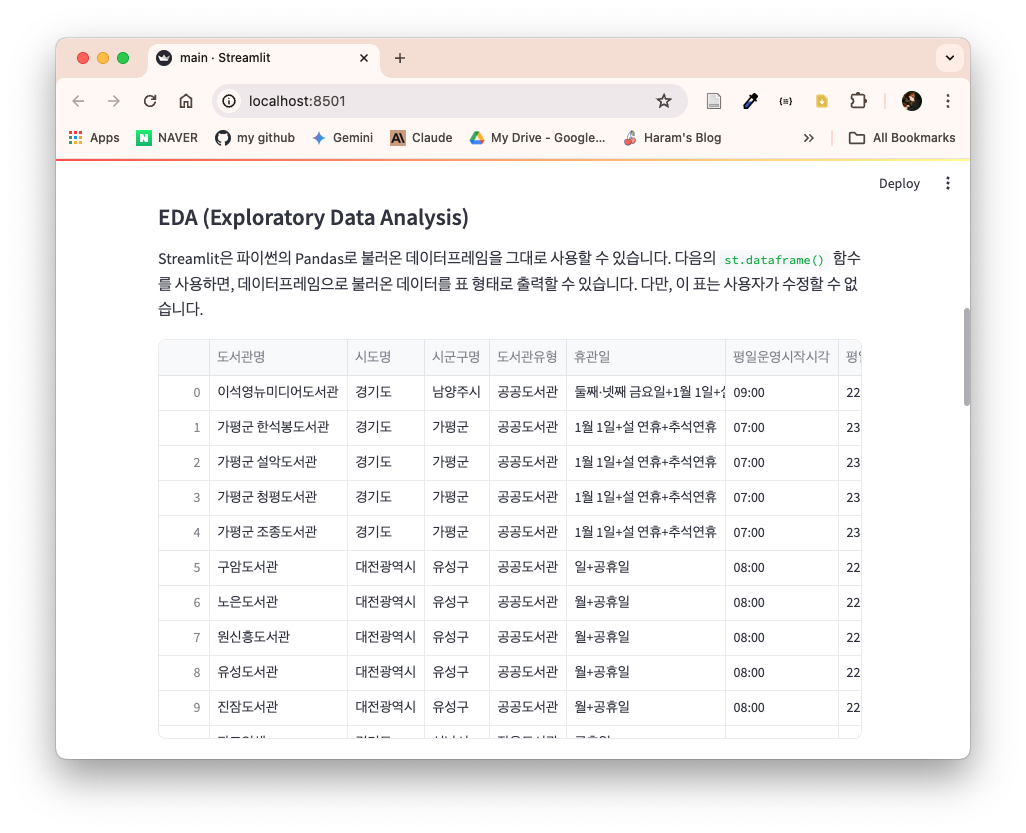
다음의 코드는 자료수(도서) 컬럼의 값 중 오류가 있는 부분을 수정하고, 해당 컬럼의 값을 int로 수정한다. st.dataframe()은 데이터프레임으로 불러온 데이터를 표 형태로 출력할 수 있다. 다만, 이 표는 사용자가 수정할 수 없는 형태다. 표 위를 호버하면, 다운로드 받거나 표 안의 값을 검색할 수 있는 기능을 제공한다.
# 1. load data
df = pd.read_csv("data/전국도서관표준데이터.csv", encoding="cp949")
# 2. 데이터 정제
df.at[3169, "자료수(도서)"] = 47698
df["자료수(도서)"] = df["자료수(도서)"].astype(int)
# 3. 전체 데이터 보여주기
st.dataframe(df)
st.data_editor & st.column_config
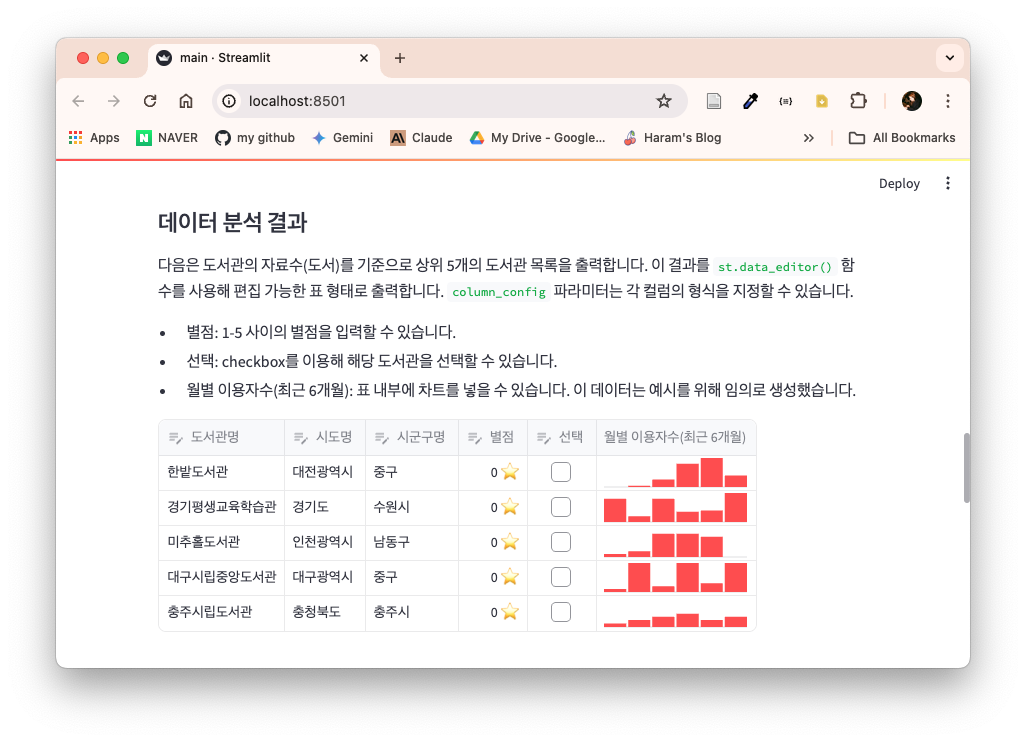
다음의 코드는 자료수(도서)를 기준으로 상위 5개의 도서관을 출력하고, '별점', '선택', '월별 이용자수'에 대한 컬럼을 추가한다. st.data_editor는 앞서 표를 수정할 수 없었던 st.dataframe과 다르게 사용자가 직접 표 수정이 가능하다. st.column_config는 컬럼에 대한 설정을 정의한다. '별점'은 NumberColumn을 사용해 최솟값과 최댓값을 설정한다. 선택은 CheckboxColumn으로 선택 여부를 체크하는 값을 지정하고, 월별 이용자수는 BarChartColumn을 사용해 바 그래프를 표현할 수 있다.
top_df = df.sort_values(by="자료수(도서)", ascending=False).head(5)
top_df = top_df[["도서관명", "시도명", "시군구명"]]
top_df["별점"] = 0
top_df["선택"] = False
# 월별 이용자수는 임의로 추가한 데이터임
users_data = [
[0, 4, 26, 80, 100, 40],
[80, 20, 80, 35, 40, 100],
[10, 20, 80, 80, 70, 0],
[10, 100, 20, 100, 30, 100],
[12, 24, 35, 46, 24, 35],
]
top_df["월별 이용자수"] = users_data
st.data_editor(
top_df,
column_config={
"별점": st.column_config.NumberColumn(
"별점",
help="도서관에 대한 별점을 입력하세요. (1-5)",
min_value=1,
max_value=5,
step=1,
format="%d ⭐",
),
"선택": st.column_config.CheckboxColumn(
"선택", help="선택 여부를 체크하세요."
),
"월별 이용자수": st.column_config.BarChartColumn(
"월별 이용자수(최근 6개월)",
help="최근 6개월 동안의 월별 이용자수입니다.",
y_min=0,
y_max=100,
),
},
hide_index=True,
)
st.bar_chart
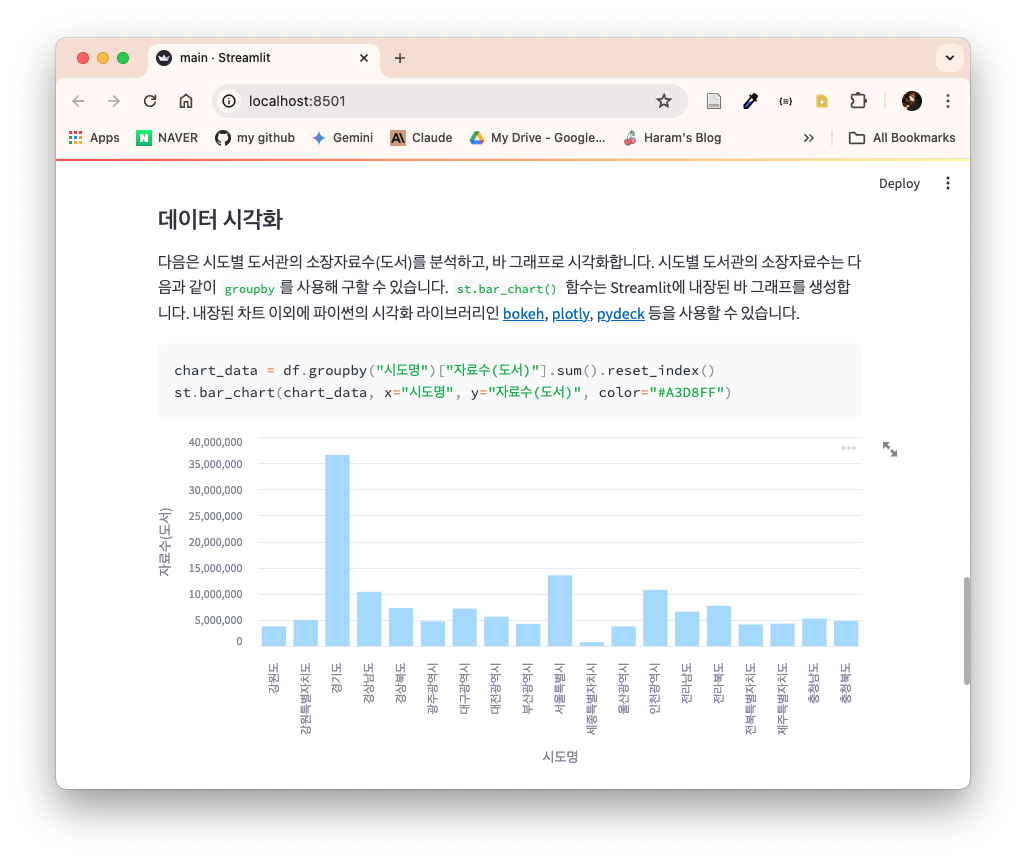
다음의 코드는 '시도명'을 기준으로 자료수(도서)를 분석한 결과를 시각화한다. st.bar_chart()는 내장된 바 차트로 데이터프레임을 시각화해준다. x에 '시도명'을 지정하고, y에 '자료수(도서)'를 설정한다. color는 바 그래프의 색을 변경할 수 있다. 내장된 차트 이외에 파이썬의 시각화 라이브러리인 bokeh, plotly, pydeck 등을 사용할 수 있다.
chart_data = df.groupby("시도명")["자료수(도서)"].sum().reset_index()
st.bar_chart(chart_data, x="시도명", y="자료수(도서)", color="#A3D8FF")
streamlit이 처음 나왔을 당시에 설치하는 과정도 조금 복잡하고, 기능이 크게 없어서 거의 사용하지 않았다. 그러나, 커뮤니티가 활성화되고 간단하게 웹 페이지를 만들 수 있는 다양한 기능과 플러그인이 생기면서 훨씬 사용하기 편해졌다. 빠르게 웹 페이지를 만들어야 할 때 streamlit을 종종 사용할 것 같다.
학부 수업 시간에 Streamlit 튜토리얼 강의를 진행했다. 간단하게 streamlit을 사용할 수 있는 방법을 중심으로 강의를 진행했다. streamlit을 실행하는 프로젝트 환경 구축부터 실제 데이터로 웹 페이지에 분석할 수 있는 방법까지 소개한다. 전체 소스코드는 깃헙의 streamlit-tutorial 레포에서 공개하고 있다.
프로젝트 환경 구축하기
streamlit는 다양한 모듈을 사용하고 있어 설치에 꽤나 애를 먹는다. 기본적으로 venv를 사용해 가상환경에서 streamlit을 실행할 수 있는 환경을 설정해주는 것이 좋다. streamlit-tutorial의 레포를 가져온 다음, 다음과 같이 설정하면 streamlit을 위한 가상환경을 생성할 수 있다. git clone 후에 streamlit-tutorial의 가장 상단의 경로에서 가상환경을 실행해야 한다는 것을 잊지말자.
# 1. git clone
git clone https://github.com/givemetarte/streamlit-tutorial.git
# 2. generate python bubble
python -m venv env
# 3. activate
source env/bin/activate # mac
env\Scripts\activate.bat # window
# 4. install dependencies
pip install -r requirements.txt
# 5. run streamlit
streamlit run main.py
localhost:8501에서 다음과 같은 화면이 나타나면 streamlit이 무사히 실행된 것이다.
데이터 분석과 시각화
데이터 분석은 공공데이터포털의 전국도서관표준데이터를 활용한다. 이 데이터로 (1) 소장자료수(도서)를 가장 많이 제공하는 상위 5개의 도서관을 출력하고, 92) 시도별 도서관의 소장자료수(도서)를 분석한다.
st.dataframe
다음의 코드는 자료수(도서) 컬럼의 값 중 오류가 있는 부분을 수정하고, 해당 컬럼의 값을 int로 수정한다. st.dataframe()은 데이터프레임으로 불러온 데이터를 표 형태로 출력할 수 있다. 다만, 이 표는 사용자가 수정할 수 없는 형태다. 표 위를 호버하면, 다운로드 받거나 표 안의 값을 검색할 수 있는 기능을 제공한다.
# 1. load data
df = pd.read_csv("data/전국도서관표준데이터.csv", encoding="cp949")
# 2. 데이터 정제
df.at[3169, "자료수(도서)"] = 47698
df["자료수(도서)"] = df["자료수(도서)"].astype(int)
# 3. 전체 데이터 보여주기
st.dataframe(df)
st.data_editor & st.column_config
다음의 코드는 자료수(도서)를 기준으로 상위 5개의 도서관을 출력하고, '별점', '선택', '월별 이용자수'에 대한 컬럼을 추가한다. st.data_editor는 앞서 표를 수정할 수 없었던 st.dataframe과 다르게 사용자가 직접 표 수정이 가능하다. st.column_config는 컬럼에 대한 설정을 정의한다. '별점'은 NumberColumn을 사용해 최솟값과 최댓값을 설정한다. 선택은 CheckboxColumn으로 선택 여부를 체크하는 값을 지정하고, 월별 이용자수는 BarChartColumn을 사용해 바 그래프를 표현할 수 있다.
top_df = df.sort_values(by="자료수(도서)", ascending=False).head(5)
top_df = top_df[["도서관명", "시도명", "시군구명"]]
top_df["별점"] = 0
top_df["선택"] = False
# 월별 이용자수는 임의로 추가한 데이터임
users_data = [
[0, 4, 26, 80, 100, 40],
[80, 20, 80, 35, 40, 100],
[10, 20, 80, 80, 70, 0],
[10, 100, 20, 100, 30, 100],
[12, 24, 35, 46, 24, 35],
]
top_df["월별 이용자수"] = users_data
st.data_editor(
top_df,
column_config={
"별점": st.column_config.NumberColumn(
"별점",
help="도서관에 대한 별점을 입력하세요. (1-5)",
min_value=1,
max_value=5,
step=1,
format="%d ⭐",
),
"선택": st.column_config.CheckboxColumn(
"선택", help="선택 여부를 체크하세요."
),
"월별 이용자수": st.column_config.BarChartColumn(
"월별 이용자수(최근 6개월)",
help="최근 6개월 동안의 월별 이용자수입니다.",
y_min=0,
y_max=100,
),
},
hide_index=True,
)
st.bar_chart
다음의 코드는 '시도명'을 기준으로 자료수(도서)를 분석한 결과를 시각화한다. st.bar_chart()는 내장된 바 차트로 데이터프레임을 시각화해준다. x에 '시도명'을 지정하고, y에 '자료수(도서)'를 설정한다. color는 바 그래프의 색을 변경할 수 있다. 내장된 차트 이외에 파이썬의 시각화 라이브러리인 bokeh, plotly, pydeck 등을 사용할 수 있다.
chart_data = df.groupby("시도명")["자료수(도서)"].sum().reset_index()
st.bar_chart(chart_data, x="시도명", y="자료수(도서)", color="#A3D8FF")
streamlit이 처음 나왔을 당시에 설치하는 과정도 조금 복잡하고, 기능이 크게 없어서 거의 사용하지 않았다. 그러나, 커뮤니티가 활성화되고 간단하게 웹 페이지를 만들 수 있는 다양한 기능과 플러그인이 생기면서 훨씬 사용하기 편해졌다. 빠르게 웹 페이지를 만들어야 할 때 streamlit을 종종 사용할 것 같다.