오픈소스 qlever로 성능 빠른 SPARQL engine 생성하기
2024. 08. 14. by 박하람
대규모의 지식그래프가 정상적으로 질의될 수 있으려면, 성능이 매우 좋은 SPARQL engine이 필요하다. 상용 트리플 스토어를 사용한다면 어느정도 SPARQL engine의 성능은 보장되어 있겠지만... 오픈소스를 사용한다면 실시간으로 SPARQL endpoint를 이용한 질의는 거의 불가능하다. 그래서 대안으로 여러가지를 찾아보던 중 오픈소스인 qlever를 발견했다. 약 한달 넘는 기간 동안 여러가지 시행착오를 겪으면서 qlever로 index를 만드는 방법과 결과를 소개한다.
qlever란
qlever는 매우 빠른 SPARQL engine이라 소개하고 있는데, wikidata와 같이 매우 큰 지식그래프를 처리할 수 있다고 설명한다. SPARQL 쿼리에 대해 맥락에 맞는 자동완성 기능을 제공하며, 텍스트 검색도 가능하다. qlever는 blazegraph나 virtuoso 같은 엔진보다 더 빠르다고 설명하고 있다. 추가적인 설명을 보고 싶다면 qlever GitHub을 참고하면 된다.
qlever 실행방법
qlever는 도커로 트리플 데이터에 대한 index를 생성하고, 이를 기반으로 실시간 SPARQL 질의를 가능하게 한다. 파이썬으로 간단하게 Qlever를 실행할 수 있는 라이브러리인 qlever-control을 제공한다. 그러나 qlever-control은 상당히 문서화가 되어 있지 않아서 실행하는 데 굉장히 고생했다. 직접 issue를 남기기도 했는데 나의 에러과정은 여기 이슈에서 확인할 수 있다. 이 라이브러리를 기준으로 qlever index를 생성하고, SPARQL 질의가 가능한 UI까지 실행하는 방법에 대해 설명한다.
qleverfile 만들기
qlever는 공개되어 있는 지식그래프를 가져오는 작업부터 시작할 수 있도록 해놓았다. 그러나 나의 경우는 내가 갖고 있는 약 9,450만 개의 트리플을 가진 지식그래프를 사용할 예정이라 qlever index부터 진행했다. qlever index를 실행하기 전에 Qleverfile을 생성해야 한다. 여기에서 예시 파일을 확인할 수 있고, 나의 경우는 아래와 같이 설정했다.
[data]
NAME = test
DESCRIPTION = test data
[index]
INPUT_FILES = *.ttl
CAT_INPUT_FILES = cat ${INPUT_FILES}
SETTINGS_JSON = { "languages-internal": [], "prefixes-external": [""], "locale": { "language": "en", "country": "US", "ignore-punctuation": true }, "ascii-prefixes-only": true, "num-triples-per-batch": 500000, "parallel-parsing" : false}
STXXL_MEMORY = 10G
[server]
PORT = 7001
ACCESS_TOKEN = ${data:NAME}
MEMORY_FOR_QUERIES = 10G
CACHE_MAX_SIZE = 6G
[runtime]
SYSTEM = docker
IMAGE = docker.io/adfreiburg/qlever:latest
[ui]
UI_CONFIG = test
여기서 주의할 점은 다음과 같다:
Qleverfile이 있는 경로에 index를 생성하려고 하는 데이터가 있어야 한다.INPUT_FILES에서 데이터의 확장자를 작성하면 된다.ttl이 아닌 압축버전 등도 가능하다. (압축을 풀지 않아도 된다)SETTINGS_JSON의num-triples-per-batch는 배치로 저장할 트리플 수를 정한다. 경험상 100k보다 많이 작성할 경우 코드를 실행하는 머신의 성능이 좋지 않으면 에러가 난다.SETTINGS_JSON의parallel-parsing은 병렬적으로 index를 생성하는 방법인데, true시 오류가 날 수 있다.STXXL_MEMORY를 설정해줘야 대규모 데이터의 index 생성시 에러가 나지 않는다.- 나머지는
Qleverfile의 예시를 보고 작성하면 된다.
index 생성하기
Qleverfile이 있는 경로에 인덱스를 생성하고 싶은 ttl 파일을 저장한다. INPUT_FILES를 *.ttl로 설정했기 때문에 모든 ttl 파일이 index에 포함된다. 다음의 코드를 입력하면 index가 생성된다. 맥 m1(SDD 500G, Memory 16G)에서 약 9,450만개의 트리플 데이터를 인덱싱하는 데 걸린 시간은 약 25분이다. 사실 인덱스를 생성하기 위해 서버 4개로 테스트해봤는데 유일하게 맥 m1 서버에서 유일하게 성공했다..🥹
qlever index
인덱스가 모두 완료된 후 qlever index-stats를 입력하면 다음과 같이 인덱스 통계정보가 출력된다. 이렇게 인덱스를 생성하면, 결과물을 모두 다른 서버로 옮긴 후 qlever start나 qlever ui의 실행도 가능하다.
Command: index-stats
Breakdown of the time used for building the index, based on the timestamps for key lines in "test.index-log.txt"
Parse input : 10.5 min
Build vocabularies : 11.0 min
Convert to global IDs : 0.8 min
Permutation SPO & SOP : 0.5 min
Permutation OSP & OPS : 1.0 min
Permutation PSO & POS : 0.8 min
TOTAL time : 24.6 min
Breakdown of the space used for building the index
Files index.* : 1.0 GB
Files vocabulary.* : 1.2 GB
TOTAL size : 2.2 GB
ui 실행하기
인덱스가 무사히 생성되고 다음의 코드를 순서대로 실행하면 된다. 인덱스가 제대로 생성되지 않을 경우에 qlever start시 에러가 생성되므로, 이 경우는 다시 인덱스를 생성해야 한다.
qlever start
qlever ui
ui 실행시 7000 포트가 안 열릴 때
qlever ui 실행 시 다음과 같은 에러가 나왔다.
docker: Error response from daemon: Ports are not available: listen tcp 0.0.0.0:7000:
bind: address already in use.
이미 7000 포트를 사용하고 있다는 에러였는데, 이유를 알아보니 mac 업그레이드 시 AirPlay가 실행되기 때문이었다. AirPlay는 5000 또는 7000 포트를 사용하고 있었는데, 다음의 방법으로 AirPlay Receiver를 해제해주면 된다. 이후 qlever ui를 실행하면 잘 동작한다.
백엔드 설정
qlever ui를 실행한 후 localhost:7000에 접속하면 qlever의 SPARQL 질의창을 볼 수 있다. 내 인덱스로 질의하려면 왼쪽 상단의 WikiData로 적힌 dropdown을 선택한 후, Add new backend를 선택한다.
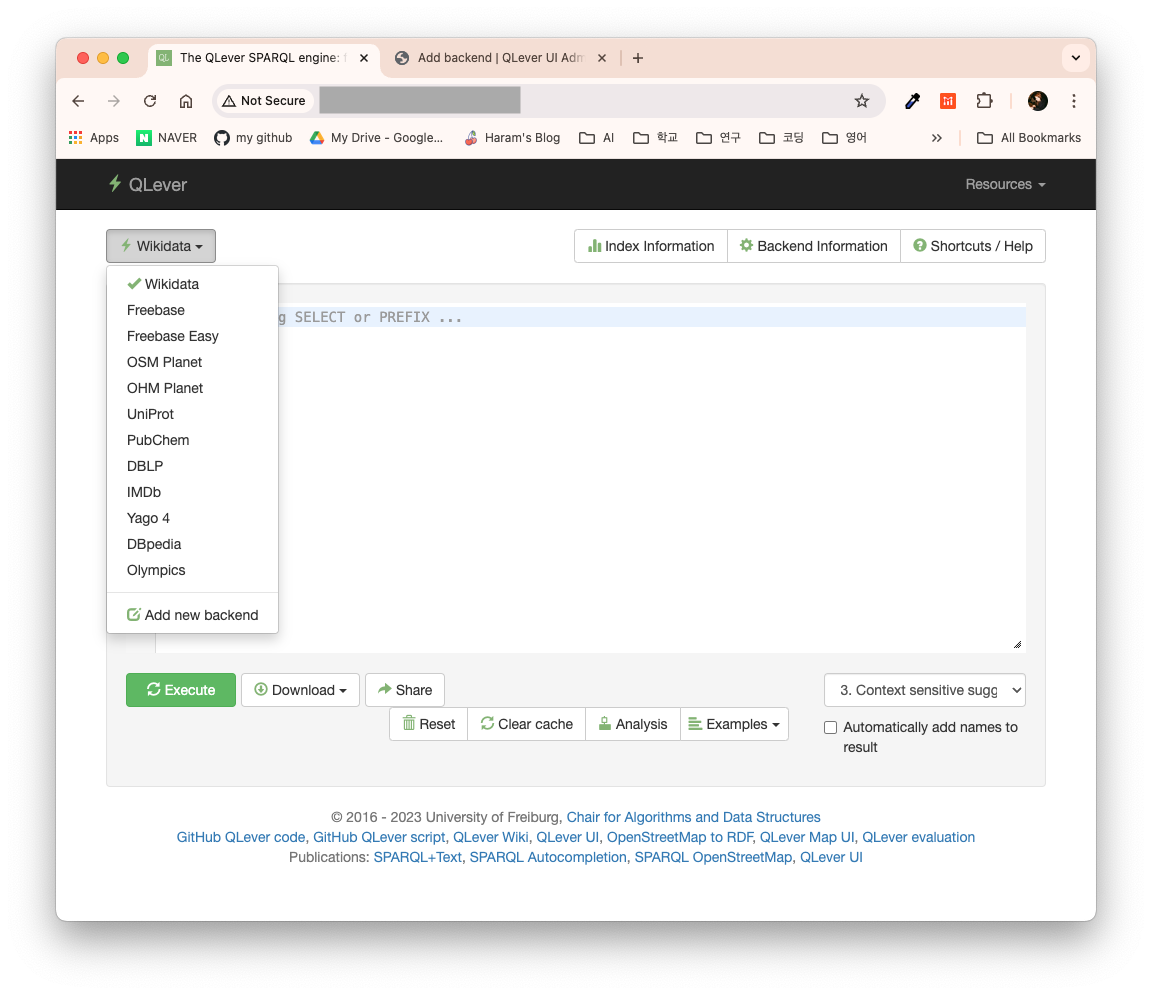
Add new backend 버튼을 클릭하면 Django의 Admin 화면이 나타난다. 초기 ID와 비밀번호는 모두 demo다. 로그인 후 아래와 같이 작성한다. slug는 URL에 표시될 경로이며, Base URL에 qlever start시 실행된 포트 경로를 입력한다.
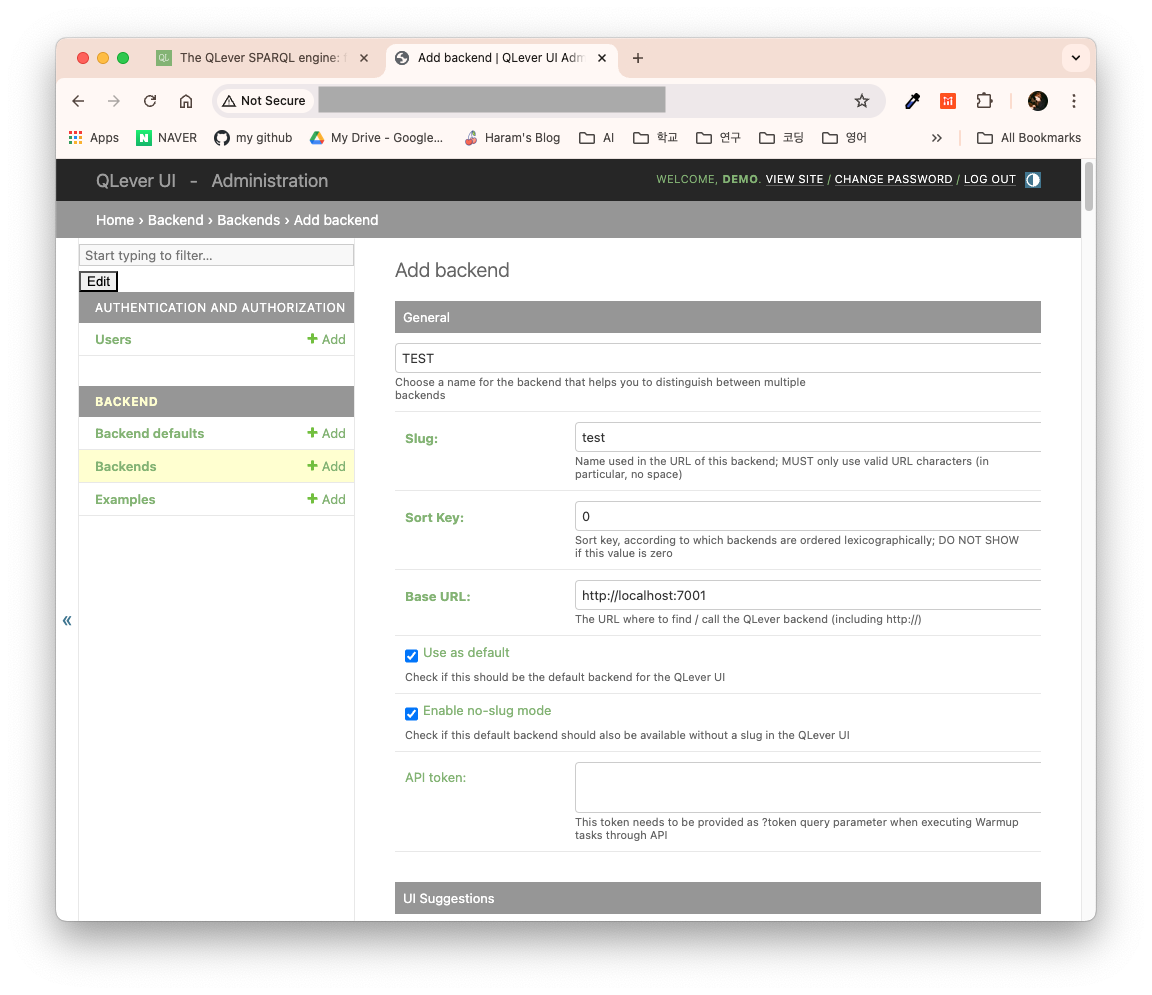
이후 설정을 완료한 후 http://localhost:7000/test로 접속하면 내 인덱스에서 SPARQL 질의를 수행할 수 있다.
SPARQL 질의 테스트
구축한 qlever index를 기반으로 blazegraph와 SPARQL 질의속도를 비교한다. 동일하게 약 9,450만개의 트리플을 blazegraph에 넣고 이 결과를 qlever의 질의결과와 비교한다. qlever와 blazegraph의 실행은 모두 10G의 메모리가 할당됐다. 추가적으로 qlever는 캐시의 최대 사이즈를 설정할 수 있어 6G로 설정했다.
| 항목 | qlever | blazegraph |
|---|---|---|
| 인덱스 생성(qlever) 또는 데이터 저장(blazegraph)에 소요된 시간 | 26 mins | 85 mins |
| SPARQL 질의1: 총 트리플 수 출력 | 3 ms | Memory error |
| SPARQL 질의2: 식별자와 레이블 조회 | 2,186 ms (2 ms) | 329 ms (195 ms) |
| SPARQL 질의3: 흑석로가 포함된 레이블 개수 | 23,099 ms (1 ms) | 4 mins (4 mins) |
SPARQL 질의1: 총 트리플 수 출력
첫번째 질의는 다음과 같이 총 트리플 수를 출력한다. qlever는 3ms만에 바로 모든 트리플의 개수를 출력하지만, blazegraph는 메모리 에러로 결과가 나오지 않았다.
SELECT (COUNT(DISTINCT ?s) AS ?triples)
WHERE {
?s ?p ?o .
}
SPARQL 질의2: 식별자와 레이블 조회
두번째 질의는 식별자와 레이블을 조회하고 20줄만 출력한다. qlever는 처음 이 쿼리 실행 시 2,186 ms가 소요되지만, 이후 동일한 쿼리를 실행하면 캐시가 저장되어 2 ms의 속도로 매우 빨라진다. blazegraph는 처음 쿼리를 실행할 때 329 ms가 걸리지만, 이후 동일한 쿼리를 실행하면 195 ms로 속도가 소폭 빨라진다.
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX dct: <http://purl.org/dc/terms/>
SELECT DISTINCT ?id ?label
WHERE {
?s rdfs:label ?label ;
dct:identifier ?id .
} LIMIT 20
SPARQL 질의3: 흑석로가 포함된 레이블 개수
세번째 질의는 '흑석로'라는 문자열이 포함된 레이블의 개수를 구한다. qlever는 처음 쿼리를 실행할 때 23,099 ms가 소요되나, 두번째로 실행할 때는 1 ms로 빨라진다. blazegraph는 처음 쿼리 실행 시 약 4 mins가 소요되고, 두번째로 질의해도 비슷하게 4 mins가 소요된다.
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT DISTINCT ?label
WHERE {
?s rdfs:label ?label .
FILTER(CONTAINS(?label, "흑석로"))
}
정리하며
qlever로 대규모의 인덱스를 생성하고, 빠른 SPARQL 질의를 수행할 수 있는 방법에 대해 알아보았다. 확실히 blazegraph보다는 질의 속도가 빠르고, SPARQL 질의 cache를 개별적으로 구축하고 있어 확실히 속도가 빠르다! 하지만 내장 ql:contains-text와 같이 full text search와 같은 작업은 좀 더 테스트해봐야 할 듯하다.
대규모의 지식그래프가 정상적으로 질의될 수 있으려면, 성능이 매우 좋은 SPARQL engine이 필요하다. 상용 트리플 스토어를 사용한다면 어느정도 SPARQL engine의 성능은 보장되어 있겠지만... 오픈소스를 사용한다면 실시간으로 SPARQL endpoint를 이용한 질의는 거의 불가능하다. 그래서 대안으로 여러가지를 찾아보던 중 오픈소스인 qlever를 발견했다. 약 한달 넘는 기간 동안 여러가지 시행착오를 겪으면서 qlever로 index를 만드는 방법과 결과를 소개한다.
qlever란
qlever는 매우 빠른 SPARQL engine이라 소개하고 있는데, wikidata와 같이 매우 큰 지식그래프를 처리할 수 있다고 설명한다. SPARQL 쿼리에 대해 맥락에 맞는 자동완성 기능을 제공하며, 텍스트 검색도 가능하다. qlever는 blazegraph나 virtuoso 같은 엔진보다 더 빠르다고 설명하고 있다. 추가적인 설명을 보고 싶다면 qlever GitHub을 참고하면 된다.
qlever 실행방법
qlever는 도커로 트리플 데이터에 대한 index를 생성하고, 이를 기반으로 실시간 SPARQL 질의를 가능하게 한다. 파이썬으로 간단하게 Qlever를 실행할 수 있는 라이브러리인 qlever-control을 제공한다. 그러나 qlever-control은 상당히 문서화가 되어 있지 않아서 실행하는 데 굉장히 고생했다. 직접 issue를 남기기도 했는데 나의 에러과정은 여기 이슈에서 확인할 수 있다. 이 라이브러리를 기준으로 qlever index를 생성하고, SPARQL 질의가 가능한 UI까지 실행하는 방법에 대해 설명한다.
qleverfile 만들기
qlever는 공개되어 있는 지식그래프를 가져오는 작업부터 시작할 수 있도록 해놓았다. 그러나 나의 경우는 내가 갖고 있는 약 9,450만 개의 트리플을 가진 지식그래프를 사용할 예정이라 qlever index부터 진행했다. qlever index를 실행하기 전에 Qleverfile을 생성해야 한다. 여기에서 예시 파일을 확인할 수 있고, 나의 경우는 아래와 같이 설정했다.
[data]
NAME = test
DESCRIPTION = test data
[index]
INPUT_FILES = *.ttl
CAT_INPUT_FILES = cat ${INPUT_FILES}
SETTINGS_JSON = { "languages-internal": [], "prefixes-external": [""], "locale": { "language": "en", "country": "US", "ignore-punctuation": true }, "ascii-prefixes-only": true, "num-triples-per-batch": 500000, "parallel-parsing" : false}
STXXL_MEMORY = 10G
[server]
PORT = 7001
ACCESS_TOKEN = ${data:NAME}
MEMORY_FOR_QUERIES = 10G
CACHE_MAX_SIZE = 6G
[runtime]
SYSTEM = docker
IMAGE = docker.io/adfreiburg/qlever:latest
[ui]
UI_CONFIG = test
여기서 주의할 점은 다음과 같다:
Qleverfile이 있는 경로에 index를 생성하려고 하는 데이터가 있어야 한다.INPUT_FILES에서 데이터의 확장자를 작성하면 된다.ttl이 아닌 압축버전 등도 가능하다. (압축을 풀지 않아도 된다)SETTINGS_JSON의num-triples-per-batch는 배치로 저장할 트리플 수를 정한다. 경험상 100k보다 많이 작성할 경우 코드를 실행하는 머신의 성능이 좋지 않으면 에러가 난다.SETTINGS_JSON의parallel-parsing은 병렬적으로 index를 생성하는 방법인데, true시 오류가 날 수 있다.STXXL_MEMORY를 설정해줘야 대규모 데이터의 index 생성시 에러가 나지 않는다.- 나머지는
Qleverfile의 예시를 보고 작성하면 된다.
index 생성하기
Qleverfile이 있는 경로에 인덱스를 생성하고 싶은 ttl 파일을 저장한다. INPUT_FILES를 *.ttl로 설정했기 때문에 모든 ttl 파일이 index에 포함된다. 다음의 코드를 입력하면 index가 생성된다. 맥 m1(SDD 500G, Memory 16G)에서 약 9,450만개의 트리플 데이터를 인덱싱하는 데 걸린 시간은 약 25분이다. 사실 인덱스를 생성하기 위해 서버 4개로 테스트해봤는데 유일하게 맥 m1 서버에서 유일하게 성공했다..🥹
qlever index
인덱스가 모두 완료된 후 qlever index-stats를 입력하면 다음과 같이 인덱스 통계정보가 출력된다. 이렇게 인덱스를 생성하면, 결과물을 모두 다른 서버로 옮긴 후 qlever start나 qlever ui의 실행도 가능하다.
Command: index-stats
Breakdown of the time used for building the index, based on the timestamps for key lines in "test.index-log.txt"
Parse input : 10.5 min
Build vocabularies : 11.0 min
Convert to global IDs : 0.8 min
Permutation SPO & SOP : 0.5 min
Permutation OSP & OPS : 1.0 min
Permutation PSO & POS : 0.8 min
TOTAL time : 24.6 min
Breakdown of the space used for building the index
Files index.* : 1.0 GB
Files vocabulary.* : 1.2 GB
TOTAL size : 2.2 GB
ui 실행하기
인덱스가 무사히 생성되고 다음의 코드를 순서대로 실행하면 된다. 인덱스가 제대로 생성되지 않을 경우에 qlever start시 에러가 생성되므로, 이 경우는 다시 인덱스를 생성해야 한다.
qlever start
qlever ui
ui 실행시 7000 포트가 안 열릴 때
qlever ui 실행 시 다음과 같은 에러가 나왔다.
docker: Error response from daemon: Ports are not available: listen tcp 0.0.0.0:7000:
bind: address already in use.
이미 7000 포트를 사용하고 있다는 에러였는데, 이유를 알아보니 mac 업그레이드 시 AirPlay가 실행되기 때문이었다. AirPlay는 5000 또는 7000 포트를 사용하고 있었는데, 다음의 방법으로 AirPlay Receiver를 해제해주면 된다. 이후 qlever ui를 실행하면 잘 동작한다.
백엔드 설정
qlever ui를 실행한 후 localhost:7000에 접속하면 qlever의 SPARQL 질의창을 볼 수 있다. 내 인덱스로 질의하려면 왼쪽 상단의 WikiData로 적힌 dropdown을 선택한 후, Add new backend를 선택한다.
Add new backend 버튼을 클릭하면 Django의 Admin 화면이 나타난다. 초기 ID와 비밀번호는 모두 demo다. 로그인 후 아래와 같이 작성한다. slug는 URL에 표시될 경로이며, Base URL에 qlever start시 실행된 포트 경로를 입력한다.
이후 설정을 완료한 후 http://localhost:7000/test로 접속하면 내 인덱스에서 SPARQL 질의를 수행할 수 있다.
SPARQL 질의 테스트
구축한 qlever index를 기반으로 blazegraph와 SPARQL 질의속도를 비교한다. 동일하게 약 9,450만개의 트리플을 blazegraph에 넣고 이 결과를 qlever의 질의결과와 비교한다. qlever와 blazegraph의 실행은 모두 10G의 메모리가 할당됐다. 추가적으로 qlever는 캐시의 최대 사이즈를 설정할 수 있어 6G로 설정했다.
| 항목 | qlever | blazegraph |
|---|---|---|
| 인덱스 생성(qlever) 또는 데이터 저장(blazegraph)에 소요된 시간 | 26 mins | 85 mins |
| SPARQL 질의1: 총 트리플 수 출력 | 3 ms | Memory error |
| SPARQL 질의2: 식별자와 레이블 조회 | 2,186 ms (2 ms) | 329 ms (195 ms) |
| SPARQL 질의3: 흑석로가 포함된 레이블 개수 | 23,099 ms (1 ms) | 4 mins (4 mins) |
SPARQL 질의1: 총 트리플 수 출력
첫번째 질의는 다음과 같이 총 트리플 수를 출력한다. qlever는 3ms만에 바로 모든 트리플의 개수를 출력하지만, blazegraph는 메모리 에러로 결과가 나오지 않았다.
SELECT (COUNT(DISTINCT ?s) AS ?triples)
WHERE {
?s ?p ?o .
}
SPARQL 질의2: 식별자와 레이블 조회
두번째 질의는 식별자와 레이블을 조회하고 20줄만 출력한다. qlever는 처음 이 쿼리 실행 시 2,186 ms가 소요되지만, 이후 동일한 쿼리를 실행하면 캐시가 저장되어 2 ms의 속도로 매우 빨라진다. blazegraph는 처음 쿼리를 실행할 때 329 ms가 걸리지만, 이후 동일한 쿼리를 실행하면 195 ms로 속도가 소폭 빨라진다.
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX dct: <http://purl.org/dc/terms/>
SELECT DISTINCT ?id ?label
WHERE {
?s rdfs:label ?label ;
dct:identifier ?id .
} LIMIT 20
SPARQL 질의3: 흑석로가 포함된 레이블 개수
세번째 질의는 '흑석로'라는 문자열이 포함된 레이블의 개수를 구한다. qlever는 처음 쿼리를 실행할 때 23,099 ms가 소요되나, 두번째로 실행할 때는 1 ms로 빨라진다. blazegraph는 처음 쿼리 실행 시 약 4 mins가 소요되고, 두번째로 질의해도 비슷하게 4 mins가 소요된다.
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT DISTINCT ?label
WHERE {
?s rdfs:label ?label .
FILTER(CONTAINS(?label, "흑석로"))
}
정리하며
qlever로 대규모의 인덱스를 생성하고, 빠른 SPARQL 질의를 수행할 수 있는 방법에 대해 알아보았다. 확실히 blazegraph보다는 질의 속도가 빠르고, SPARQL 질의 cache를 개별적으로 구축하고 있어 확실히 속도가 빠르다! 하지만 내장 ql:contains-text와 같이 full text search와 같은 작업은 좀 더 테스트해봐야 할 듯하다.