파이썬으로 String Metric을 사용한 단어의 유사성 평가하기
2024. 03. 22. by 박하람
이전 포스팅 문자열 유사성을 측정하는 String Metric 알고리즘에서 컬럼명의 유사성을 측정할 수 있는 Metric으로 Jaro-Wrinkler를 소개했었다. 태스크의 목표는 약 9만개의 공공데이터 컬럼명 중에서 주소 값을 가질 것으로 예상되는 컬럼명(이후 주소컬럼명으로 정의)을 추출하는 것이다. 즉, '소재지도로명주소'와 '소재지지번주소', '소재지'와 같은 컬럼명이 주소컬럼명이 된다. 이전 포스팅은 Jaro-Wrinkler로 유사성을 측정하되, 그 기준이 개별 문자열(character)일지, 토큰(token) 기준일지는 빈 공간으로 남겨뒀었다. 오늘 포스팅은 파이썬을 사용해 문자열 또는 토큰 기준으로 Jaro-Wrinkler 유사성을 측정한다.
유사성 측정 방법
유사성 측정의 기준이 되는 주소컬럼명 선정
약 9만 개의 컬럼명 중에서 주소컬럼명을 찾으려면, 기준이 되는 컬럼명이 필요하다. 이를 위해 행정안전부의 공통표준용어에서 주소와 관련된 컬럼명을 추출했다. 공통표준용어는 공공데이터와 관련된 용어를 표준화한 목록으로, 개별 정부기관이 운영하는 데이터베이스의 컬럼명을 기반으로 구축됐다. 공공데이터의 컬럼명과 직접적인 관련이 없을 수 있지만, 개방되는 공공데이터가 정부기관의 데이터베이스로부터 추출되기 때문에 대표적인 주소컬럼명 예시로 사용할 수 있다고 판단했다. 총 731개의 공통표준용어 중에서 직접 보고 주소와 관련된 컬럼명을 선정했다. 주소컬럼명은 총 37개로, 다음과 같은 컬럼명을 포함한다.
- 차고지도로명주소, 소재지도로명주소, 생산지도로명주소, 시작지점도로명주소, 사업장도로명주소, 교육장도로명주소, 소재지도로명, 종료지점소재지도로명주소, 생산지지번주소, 종료지점소재지지번주소, 소재지지번주소, 사업장지번주소, 시작지점소재지지번주소, 차고지지번주소,소재지도로 등
유사도 계산
Jaro-Wrinkler는 두 단어 사이의 문자열 유사성을 계산한다. 약 9만개의 컬럼명마다 총 37개의 주소컬럼명과 유사성을 측정해야 하는데, 개별 컬럼명이 최종적으로 주소컬럼명과 유사한 정도를 측정하는 메트릭은 다음과 같다. 컬럼명 사이의 유사성을 측정하는 JaroWinkler는 jarowinkler 모듈을 사용한다. 하나의 컬럼명에 대해 총 37개의 공통표준용어와 유사성을 측정하고, 이에 대해 '_score'라는 컬럼명의 값으로 담아둔다. 총 37개의 용어와 유사성을 비교한 것 중에서 상위 3개의 점수를 추출하고 평균을 계산하는 것이 최종 점수다. 즉, 가장 높게 나온 상위 3개의 JaroWrinkler 점수의 평균을 구한 것이 최종적인 유사도 점수가 된다.
from jarowinkler import jarowinkler_similarity
def get_jw_score(keyword, col):
return jarowinkler_similarity(keyword, str(col))
top_scores = char_df.filter(regex='_score$').apply(lambda col: col.nlargest(3).mean(), axis=1)
평가 방법
최종적인 JaroWrinkler의 유사성 점수가 적절한지를 검증하는 것이 필요하다. 약 9만개의 컬럼명 중에서 주소컬럼명으로 직접 레이블링한 데이터가 존재한다. 약 9만개 중 주소컬럼명으로 선정된 것은 약 849개다. 최종적인 JaroWrinkler 유사성 점수를 주소예측값이라고 할 때, 이 주소예측값이 특정 값(x)를 넘는다면 주소컬럼명으로 정의한다. JaroWrinkler로 예측한 주소컬럼명과 실제 주소컬럼명인지 비교한다.
문자열(character) 기준의 유사성 측정
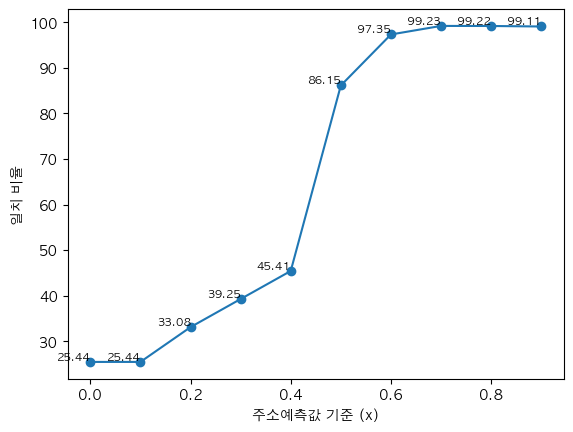
JaroWrinkler 유사성을 계산할 때, 기본적으로 문자열을 기준으로 계산한다. 예를 들어, '도로명주소'와 '소재지도로명주소'는 '도'와 '소'와 같이 하나의 문자열 기준으로 계산한다는 의미다. 다음 그림은 주소컬럼명으로 정의하는 x의 값이 변화하면서 주소컬럼명을 잘 예측할 수 있는지 나타낸다. 가장 최적의 x는 0.7로, 99.23%라는 일치율을 보인다.
토큰(token) 기준의 유사성 측정
다음은 토큰을 기준으로 JaroWrinkler의 유사성을 측정한다. 컬럼명은 일반적으로 명사의 조합이기 때문에, 명사를 중심으로 유사성을 측정하는 방법이 더 적절할 수 있다. 다음 코드는 형태소 분석기 kiwi를 사용해서 컬럼명을 토큰화하고, 명사형의 토큰만 남겨 리스트로 만든다. 예를 들어, '면적킬로미터'는 ['면적','킬로미터']로 토큰화된다.
from kiwipiepy import Kiwi
kiwi = Kiwi()
def tokenizer(keyword):
token_list = []
for t in kiwi.analyze(str(keyword))[0][0]:
if (t.form) and (t.tag.startswith('NN')):
token_list.append(t.form)
return token_list
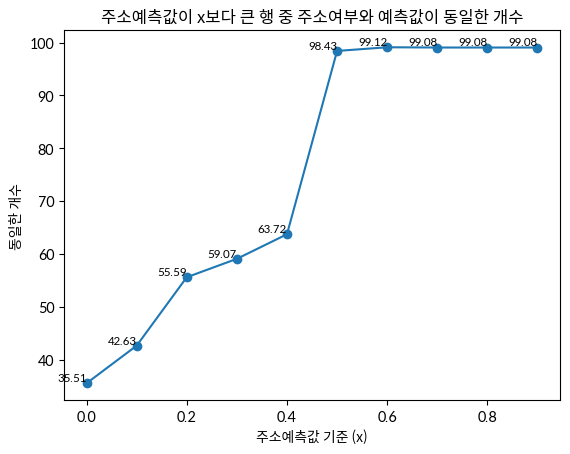
토큰을 기준으로 JaroWrinkler의 유사성을 계산한 결과는 다음 그림과 같다. 가장 높은 일치율을 보이는 x는 0.6으로, 99.12%라는 일치율을 보인다.
정리하며
Jaro-Wrinkler로 유사성을 측정한 결과를 바탕으로 정리하면서 느낀점은 다음과 같다.
- 토큰 단위보단 문자열 단위의 유사성 계산이 더 나을수도: 둘 중 가장 높은 일치율은 문자열 단위에서 나왔다. 토큰 단위는 전반적으로 높은 점수를 보이지만, 토큰화 하는 과정에서 명사가 적절히 추출되지 않았을 가능성도 있다(실제로 '주소'가 포함되었음에도 명사로 추출하지 않은 컬럼명도 있었다). 컬럼명이 짧기 때문일 수도 있고, kiwi가 아닌 다른 형태소 분석기로 테스트해보는 방법도 있다.
- 평가방법이 적절한가?: 약 9만개의 컬럼명 중에서 주소컬럼명에 해당하는 건 약 800개 정도다. 즉, 아주 극히 일부만 주소컬럼명에 해당하는데, 이 경우는 데이터의 분포가 극단적이라 일치율이 높이 나올 수밖에 없다. 극단적인 데이터 분포를 갖고 있는 예측에 대한 검증은 F1 score나 precision 등의 검증 방법을 사용하는 것이 더 적절할 수 있다.
- 정확도가 더 중요한 주소컬럼명 추출: 이 태스크를 수행한 이유는 데이터세트에서 주소컬럼명을 선정한 다음, 실제로 주소 값이 포함된 데이터세트를 찾기 위해서다. 이를 위해서는 무엇보다 추출한 주소컬럼명이 실제 주소 값을 갖고 있는지가 중요하다. 위와 같이 유사도를 측정한 방식은 약 9만개의 컬럼명 중에서 어느정도 주소와 관련된 컬럼명을 골라줄 수 있겠지만, 실제로 주소와 관련되지 않은 값을 포함할 가능성이 높다. 실제 주소와 관련된 컬럼명으로 예측된 컬럼명 중에 '링크주소', '홈페이지주소'와 같이 동음이의어가 포함된 컬럼명이 많았다. 결국은 수작업이 다시 들어가야 하는 상황...🥲
이전 포스팅 문자열 유사성을 측정하는 String Metric 알고리즘에서 컬럼명의 유사성을 측정할 수 있는 Metric으로 Jaro-Wrinkler를 소개했었다. 태스크의 목표는 약 9만개의 공공데이터 컬럼명 중에서 주소 값을 가질 것으로 예상되는 컬럼명(이후 주소컬럼명으로 정의)을 추출하는 것이다. 즉, '소재지도로명주소'와 '소재지지번주소', '소재지'와 같은 컬럼명이 주소컬럼명이 된다. 이전 포스팅은 Jaro-Wrinkler로 유사성을 측정하되, 그 기준이 개별 문자열(character)일지, 토큰(token) 기준일지는 빈 공간으로 남겨뒀었다. 오늘 포스팅은 파이썬을 사용해 문자열 또는 토큰 기준으로 Jaro-Wrinkler 유사성을 측정한다.
유사성 측정 방법
유사성 측정의 기준이 되는 주소컬럼명 선정
약 9만 개의 컬럼명 중에서 주소컬럼명을 찾으려면, 기준이 되는 컬럼명이 필요하다. 이를 위해 행정안전부의 공통표준용어에서 주소와 관련된 컬럼명을 추출했다. 공통표준용어는 공공데이터와 관련된 용어를 표준화한 목록으로, 개별 정부기관이 운영하는 데이터베이스의 컬럼명을 기반으로 구축됐다. 공공데이터의 컬럼명과 직접적인 관련이 없을 수 있지만, 개방되는 공공데이터가 정부기관의 데이터베이스로부터 추출되기 때문에 대표적인 주소컬럼명 예시로 사용할 수 있다고 판단했다. 총 731개의 공통표준용어 중에서 직접 보고 주소와 관련된 컬럼명을 선정했다. 주소컬럼명은 총 37개로, 다음과 같은 컬럼명을 포함한다.
- 차고지도로명주소, 소재지도로명주소, 생산지도로명주소, 시작지점도로명주소, 사업장도로명주소, 교육장도로명주소, 소재지도로명, 종료지점소재지도로명주소, 생산지지번주소, 종료지점소재지지번주소, 소재지지번주소, 사업장지번주소, 시작지점소재지지번주소, 차고지지번주소,소재지도로 등
유사도 계산
Jaro-Wrinkler는 두 단어 사이의 문자열 유사성을 계산한다. 약 9만개의 컬럼명마다 총 37개의 주소컬럼명과 유사성을 측정해야 하는데, 개별 컬럼명이 최종적으로 주소컬럼명과 유사한 정도를 측정하는 메트릭은 다음과 같다. 컬럼명 사이의 유사성을 측정하는 JaroWinkler는 jarowinkler 모듈을 사용한다. 하나의 컬럼명에 대해 총 37개의 공통표준용어와 유사성을 측정하고, 이에 대해 '_score'라는 컬럼명의 값으로 담아둔다. 총 37개의 용어와 유사성을 비교한 것 중에서 상위 3개의 점수를 추출하고 평균을 계산하는 것이 최종 점수다. 즉, 가장 높게 나온 상위 3개의 JaroWrinkler 점수의 평균을 구한 것이 최종적인 유사도 점수가 된다.
from jarowinkler import jarowinkler_similarity
def get_jw_score(keyword, col):
return jarowinkler_similarity(keyword, str(col))
top_scores = char_df.filter(regex='_score$').apply(lambda col: col.nlargest(3).mean(), axis=1)
평가 방법
최종적인 JaroWrinkler의 유사성 점수가 적절한지를 검증하는 것이 필요하다. 약 9만개의 컬럼명 중에서 주소컬럼명으로 직접 레이블링한 데이터가 존재한다. 약 9만개 중 주소컬럼명으로 선정된 것은 약 849개다. 최종적인 JaroWrinkler 유사성 점수를 주소예측값이라고 할 때, 이 주소예측값이 특정 값(x)를 넘는다면 주소컬럼명으로 정의한다. JaroWrinkler로 예측한 주소컬럼명과 실제 주소컬럼명인지 비교한다.
문자열(character) 기준의 유사성 측정
JaroWrinkler 유사성을 계산할 때, 기본적으로 문자열을 기준으로 계산한다. 예를 들어, '도로명주소'와 '소재지도로명주소'는 '도'와 '소'와 같이 하나의 문자열 기준으로 계산한다는 의미다. 다음 그림은 주소컬럼명으로 정의하는 x의 값이 변화하면서 주소컬럼명을 잘 예측할 수 있는지 나타낸다. 가장 최적의 x는 0.7로, 99.23%라는 일치율을 보인다.
토큰(token) 기준의 유사성 측정
다음은 토큰을 기준으로 JaroWrinkler의 유사성을 측정한다. 컬럼명은 일반적으로 명사의 조합이기 때문에, 명사를 중심으로 유사성을 측정하는 방법이 더 적절할 수 있다. 다음 코드는 형태소 분석기 kiwi를 사용해서 컬럼명을 토큰화하고, 명사형의 토큰만 남겨 리스트로 만든다. 예를 들어, '면적킬로미터'는 ['면적','킬로미터']로 토큰화된다.
from kiwipiepy import Kiwi
kiwi = Kiwi()
def tokenizer(keyword):
token_list = []
for t in kiwi.analyze(str(keyword))[0][0]:
if (t.form) and (t.tag.startswith('NN')):
token_list.append(t.form)
return token_list
토큰을 기준으로 JaroWrinkler의 유사성을 계산한 결과는 다음 그림과 같다. 가장 높은 일치율을 보이는 x는 0.6으로, 99.12%라는 일치율을 보인다.
정리하며
Jaro-Wrinkler로 유사성을 측정한 결과를 바탕으로 정리하면서 느낀점은 다음과 같다.
- 토큰 단위보단 문자열 단위의 유사성 계산이 더 나을수도: 둘 중 가장 높은 일치율은 문자열 단위에서 나왔다. 토큰 단위는 전반적으로 높은 점수를 보이지만, 토큰화 하는 과정에서 명사가 적절히 추출되지 않았을 가능성도 있다(실제로 '주소'가 포함되었음에도 명사로 추출하지 않은 컬럼명도 있었다). 컬럼명이 짧기 때문일 수도 있고, kiwi가 아닌 다른 형태소 분석기로 테스트해보는 방법도 있다.
- 평가방법이 적절한가?: 약 9만개의 컬럼명 중에서 주소컬럼명에 해당하는 건 약 800개 정도다. 즉, 아주 극히 일부만 주소컬럼명에 해당하는데, 이 경우는 데이터의 분포가 극단적이라 일치율이 높이 나올 수밖에 없다. 극단적인 데이터 분포를 갖고 있는 예측에 대한 검증은 F1 score나 precision 등의 검증 방법을 사용하는 것이 더 적절할 수 있다.
- 정확도가 더 중요한 주소컬럼명 추출: 이 태스크를 수행한 이유는 데이터세트에서 주소컬럼명을 선정한 다음, 실제로 주소 값이 포함된 데이터세트를 찾기 위해서다. 이를 위해서는 무엇보다 추출한 주소컬럼명이 실제 주소 값을 갖고 있는지가 중요하다. 위와 같이 유사도를 측정한 방식은 약 9만개의 컬럼명 중에서 어느정도 주소와 관련된 컬럼명을 골라줄 수 있겠지만, 실제로 주소와 관련되지 않은 값을 포함할 가능성이 높다. 실제 주소와 관련된 컬럼명으로 예측된 컬럼명 중에 '링크주소', '홈페이지주소'와 같이 동음이의어가 포함된 컬럼명이 많았다. 결국은 수작업이 다시 들어가야 하는 상황...🥲