파이썬으로 코헨의 카파 계수(Cohen's Kappa efficient) 계산하기
2024. 02. 08. by 박하람
데이터 분석 분야에서 실험의 결과를 검증하는 것은 무척 중요하다. 현재 나의 태스크는 데이터세트에서 추출한 컬럼명에 대해 3가지의 카테고리로 분류하고, 이 분류 결과가 적절한지 검증하는 것이다. 검증 방법으로 떠오른 대표적인 방법이 바로 코헨의 카파 계수(Cohen's Kappa efficient)다. 코헨의 카파 계수는 두 평가자 사이의 신뢰도를 측정하는 방법인데, 머신러닝 또는 딥러닝 모델의 분류결과에 대해 신뢰도를 검증하는 방법으로 사용되고 있다. 이번 포스팅은 코헨의 카파 계수의 개념과 메트릭을 알아보고, 파이썬으로 카파 계수를 계산하는 방법을 제공한다.
코헨의 카파 계수
코헨의 카파 계수는 범주형(category) 항목에 대한 평가자 사이의 신뢰도를 측정하는 데 사용되는 통계다. 2명의 평가자가 수행한 결과에 대한 신뢰도를 측정하는 것으로, 두 평가자의 평가 결과가 얼마나 일치하는지를 측정하는 척도다. 3명 이상의 신뢰도는 플레이스의 카파 계수(Fleiss' Kappa efficient)를 사용해야 한다.
카파 계수를 분석하기 위한 조건은 다음과 같다:
- 명목척도로 측정된 범주형 데이터: 예, 아니오와 같이 범주형으로 평가된 데이터여야 한다. 범주형은 개별 항목마다 우선순위가 부여되지 않으므로 가중치가 부여되지 않는 카파 계수(unweighted kappa efficient)다. 반면, 서열 척도(1순위, 2순위, 3순위)의 경우는 가중치가 부여된 카파 계수(weighted kappa efficient)를 사용한다.
- 두 평가자가 동일한 범주로 측정한 데이터: 두 평가자가 특정 항목을 평가할 때 동일한 범주로 측정해야 한다. 예를 들어, 평가자1이 '예, 아니오'라는 2가지 항목으로 평가했다면, 평가자2도 '예, 아니오'로 항목을 평가해야 한다.
Metric
코헨의 카파 계수를 라고 할 때, 다음의 수식으로 를 구한다.
- 는 2명의 평가자가 평가한 결과가 일치할 확률이다.
- 는 두 평가자가 우연히 일치하게 평가를 할 확률(hypothetical probability)이다.
- 는 값이 0이면 두 평가자의 일치가 전혀 없고, 값이 1이면 두 평가자의 평가가 모두 일치한다.
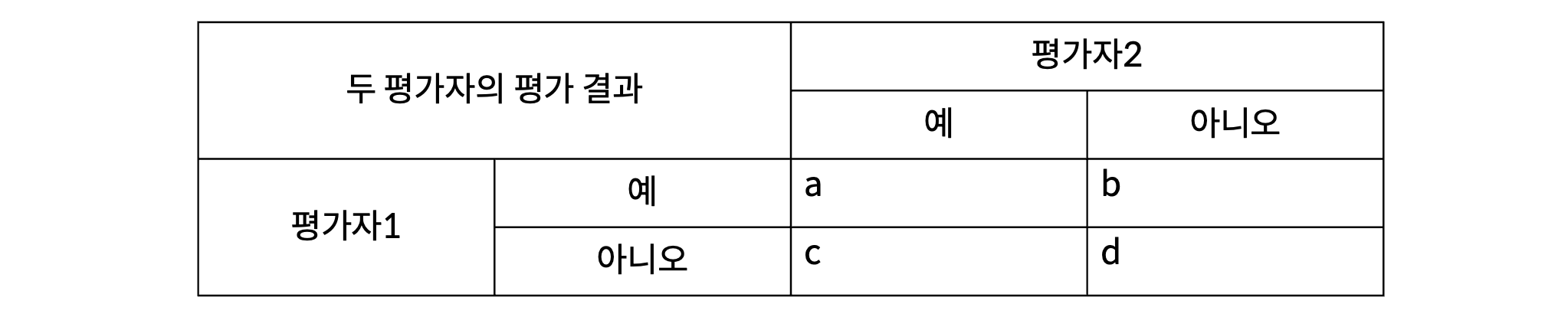
간단히 위의 표로 와 를 계산해보자.
은 전체 평가한 항목에서 평가자1과 평가자2가 모두 동일하게 '예'라고 답한 와 '아니오'라고 답한 가 포함된 비율이다.
는 개별 평가자가 예로 응답한 와 아니오로 응답한 를 더한 값이다. 즉, 는 평가자1과 평가자2가 각각 예로 응답한 비율을 곱한 값이고, 는 각각 아니오로 응답한 비율을 곱한 값이다.
카파 계수의 해석
카파 계수의 해석은 Landis & Koch(1977)의 해석을 따른다. 다음은 Landis & Koch(1977)가 제안한 해석결과다. 카파 계수가 0.2 이하라면 아주 작은 정도로 일치를 보이고, 0.8보다 크다면 거의 일치하는 수준을 보인다는 의미다.
| Kappa | Interpretation |
|---|---|
| .00 - .20 | Slight |
| .21 - .40 | Fair |
| .41 - .60 | Moderate |
| .61 - .80 | Substantial |
| >.80 | Almost Perfect |
파이썬으로 카파 계수 구하기
파이썬으로 카파 계수를 구하는 방법은 매우 간단하다. sklearn에서 제공하는 cohen_kappa_score1를 사용하면 된다. 직접 내 데이터로 평가한 결과는 다음과 같다.
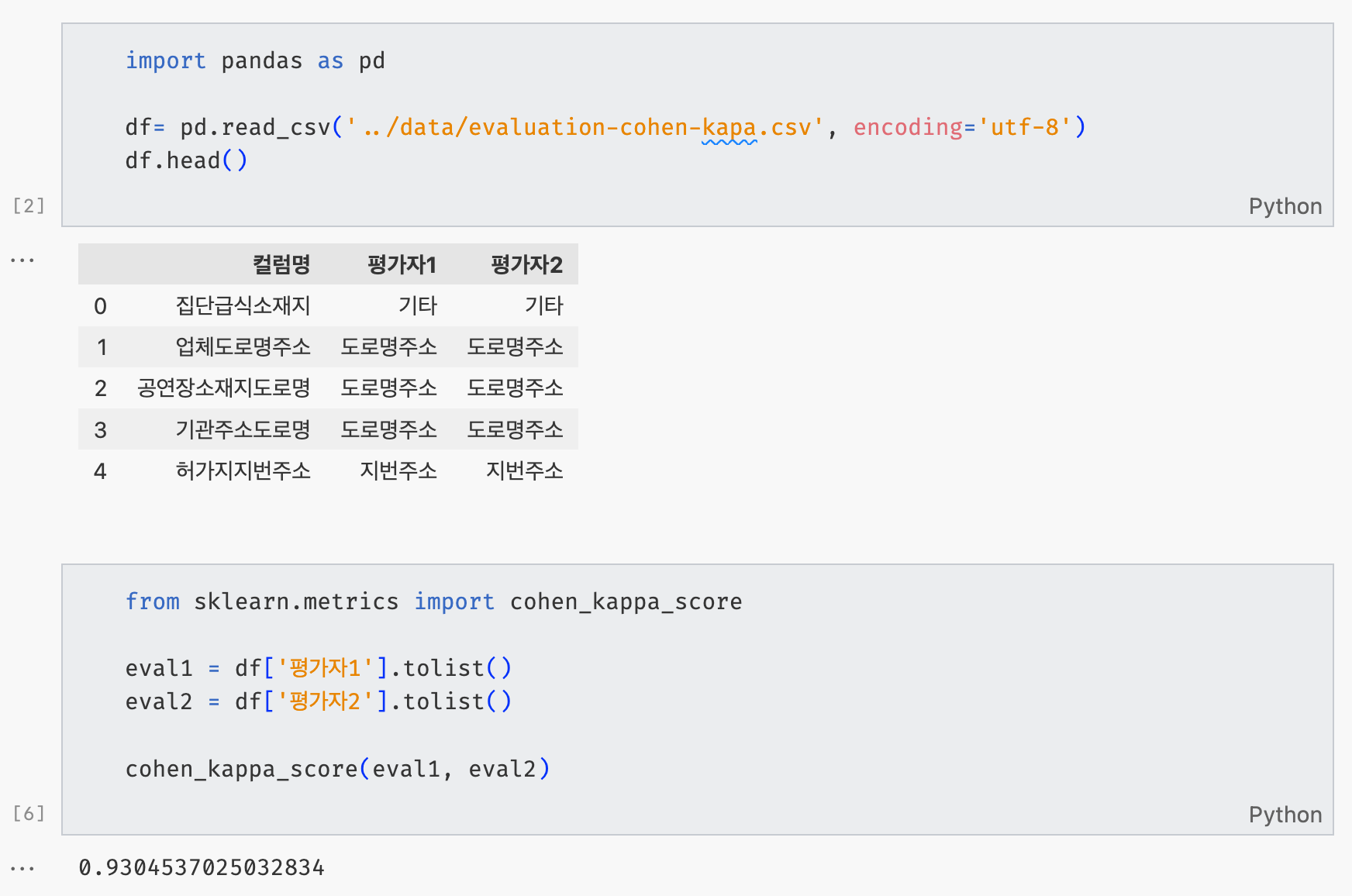
df로 불러온 데이터는 개별 컬럼명에 대해서 2명의 평가자가 도로명주소/지번주소/기타의 카테고리로 분류한 것이다. eval1과 eval2는 평가한 목록을 파이썬 리스트 형태로 변환한 것이다. 두 변수를 cohen_kappa_score에 넣어주면, 카파 계수의 값이 계산된다. 이 카파 계수의 결과를 해석하면, 두 평가자의 개별 컬럼명에 대한 카테고리의 평가는 거의 일치한다.
참고문헌
- [SPSS 24] Cohen's Kappa 계수, 도시마법사. 바로가기
- Cohen's kappa, Wikipedia. 바로가기
- Landis, J. R., & Koch, G. G. (1977). The Measurement of Observer Agreement for Categorical Data. Biometrics, 33(1), 159–174. https://doi.org/10.2307/2529310
데이터 분석 분야에서 실험의 결과를 검증하는 것은 무척 중요하다. 현재 나의 태스크는 데이터세트에서 추출한 컬럼명에 대해 3가지의 카테고리로 분류하고, 이 분류 결과가 적절한지 검증하는 것이다. 검증 방법으로 떠오른 대표적인 방법이 바로 코헨의 카파 계수(Cohen's Kappa efficient)다. 코헨의 카파 계수는 두 평가자 사이의 신뢰도를 측정하는 방법인데, 머신러닝 또는 딥러닝 모델의 분류결과에 대해 신뢰도를 검증하는 방법으로 사용되고 있다. 이번 포스팅은 코헨의 카파 계수의 개념과 메트릭을 알아보고, 파이썬으로 카파 계수를 계산하는 방법을 제공한다.
코헨의 카파 계수
코헨의 카파 계수는 범주형(category) 항목에 대한 평가자 사이의 신뢰도를 측정하는 데 사용되는 통계다. 2명의 평가자가 수행한 결과에 대한 신뢰도를 측정하는 것으로, 두 평가자의 평가 결과가 얼마나 일치하는지를 측정하는 척도다. 3명 이상의 신뢰도는 플레이스의 카파 계수(Fleiss' Kappa efficient)를 사용해야 한다.
카파 계수를 분석하기 위한 조건은 다음과 같다:
- 명목척도로 측정된 범주형 데이터: 예, 아니오와 같이 범주형으로 평가된 데이터여야 한다. 범주형은 개별 항목마다 우선순위가 부여되지 않으므로 가중치가 부여되지 않는 카파 계수(unweighted kappa efficient)다. 반면, 서열 척도(1순위, 2순위, 3순위)의 경우는 가중치가 부여된 카파 계수(weighted kappa efficient)를 사용한다.
- 두 평가자가 동일한 범주로 측정한 데이터: 두 평가자가 특정 항목을 평가할 때 동일한 범주로 측정해야 한다. 예를 들어, 평가자1이 '예, 아니오'라는 2가지 항목으로 평가했다면, 평가자2도 '예, 아니오'로 항목을 평가해야 한다.
Metric
코헨의 카파 계수를 라고 할 때, 다음의 수식으로 를 구한다.
- 는 2명의 평가자가 평가한 결과가 일치할 확률이다.
- 는 두 평가자가 우연히 일치하게 평가를 할 확률(hypothetical probability)이다.
- 는 값이 0이면 두 평가자의 일치가 전혀 없고, 값이 1이면 두 평가자의 평가가 모두 일치한다.
간단히 위의 표로 와 를 계산해보자.
은 전체 평가한 항목에서 평가자1과 평가자2가 모두 동일하게 '예'라고 답한 와 '아니오'라고 답한 가 포함된 비율이다.
는 개별 평가자가 예로 응답한 와 아니오로 응답한 를 더한 값이다. 즉, 는 평가자1과 평가자2가 각각 예로 응답한 비율을 곱한 값이고, 는 각각 아니오로 응답한 비율을 곱한 값이다.
카파 계수의 해석
카파 계수의 해석은 Landis & Koch(1977)의 해석을 따른다. 다음은 Landis & Koch(1977)가 제안한 해석결과다. 카파 계수가 0.2 이하라면 아주 작은 정도로 일치를 보이고, 0.8보다 크다면 거의 일치하는 수준을 보인다는 의미다.
| Kappa | Interpretation |
|---|---|
| .00 - .20 | Slight |
| .21 - .40 | Fair |
| .41 - .60 | Moderate |
| .61 - .80 | Substantial |
| >.80 | Almost Perfect |
파이썬으로 카파 계수 구하기
파이썬으로 카파 계수를 구하는 방법은 매우 간단하다. sklearn에서 제공하는 cohen_kappa_score1를 사용하면 된다. 직접 내 데이터로 평가한 결과는 다음과 같다.
df로 불러온 데이터는 개별 컬럼명에 대해서 2명의 평가자가 도로명주소/지번주소/기타의 카테고리로 분류한 것이다. eval1과 eval2는 평가한 목록을 파이썬 리스트 형태로 변환한 것이다. 두 변수를 cohen_kappa_score에 넣어주면, 카파 계수의 값이 계산된다. 이 카파 계수의 결과를 해석하면, 두 평가자의 개별 컬럼명에 대한 카테고리의 평가는 거의 일치한다.
참고문헌
- [SPSS 24] Cohen's Kappa 계수, 도시마법사. 바로가기
- Cohen's kappa, Wikipedia. 바로가기
- Landis, J. R., & Koch, G. G. (1977). The Measurement of Observer Agreement for Categorical Data. Biometrics, 33(1), 159–174. https://doi.org/10.2307/2529310