KCI 논문의 서지 메타데이터를 얻는 3가지 방법 (feat. Easy Scraper와 Python)
2024. 03. 21. by 박하람
최근에 크롬 익스텐션인 Easy Scraper라는 크롤링 도구를 알게됐다. 테스트 해볼 겸 수업시간의 과제에 활용해보았다. 텍스트 분석을 위해 논문의 서지 메타데이터를 수집해야 했는데, 간단하게 수집한 방법을 설명한다. 추가적으로 텍스톰으로 수집하거나 정제한 데이터의 한계를 설명한다.
데이터 수집 출처
논문의 서지데이터는 2가지의 출처를 활용했다. 첫째, DBpia의 검색 결과를 크롤링한다. DBpia는 논문의 메타데이터에 대해 다운로드 기능을 제공하지 않아서 Easy Scraper로 크롤링한다. 둘째, KCI에서 서지 메타데이터를 다운로드 받는다. KCI는 키워드 검색한 결과에 해당하는 논문의 서지사항을 엑셀로 다운로드 받을 수 있다. 약 19개의 메타데이터(예: 제목, URL, 저자, 학술지명)를 제공하지만, 초록은 제공하지 않는다.
Easy Scraper 설치
크롬 웹 스토어에서 Easy Scraper를 다운로드 받으면 된다. 설치 이후 크롬 브라우저 상단의 툴바에서 Easy Scraper를 확인할 수 있다.
(1) DBpia에서 메타데이터 크롤링하기
DBpia에서 원하는 키워드를 검색한 후, 해당 페이지에서 Easy Scraper를 클릭하면 다음과 같은 창이 나타난다. (아마) html의 li 또는 table을 인식하기 때문에 본인이 의도하지 않는 구역으로 크롤링될 수 있다. 그럴 때는 크롤링된 표 위에 있는 Change List 버튼을 클릭하고, 크롤링하고 싶은 구역을 선택하면 된다(크롤링 영역이 노란색으로 변한다). 페이지별로 크롤링을 하고 싶다면, Action to load items 아래의 토글 버튼에서 'click link to navigate to next page'를 선택한다. 파란색 Select 버튼을 누르고, 다음 페이지에 해당하는 버튼을 클릭한 다음 Start Scraping 버튼을 클릭하면 된다(페이지가 끝날 때까지 같은 것을 반복한다). 크롤링이 끝났다면 표 상단의 CSV 또는 JSON 버튼을 클릭해 데이터를 다운받는다.
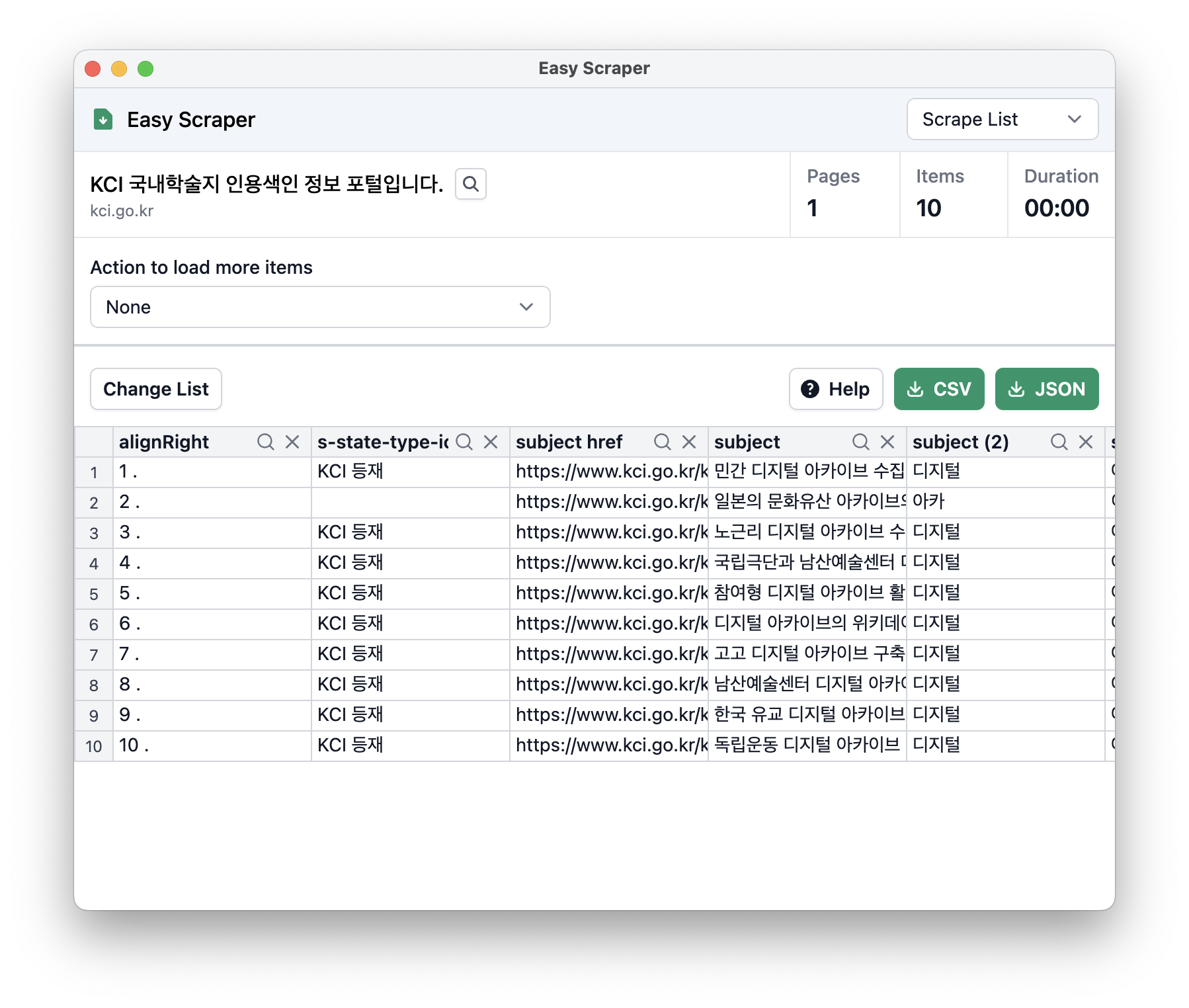
다만, 이렇게 다운로드 받은 데이터는 웹 페이지에 표시된 것을 그대로 긁은 것이기 때문에 상당한 정제가 필요하다. 엑셀이나 파이썬 등을 사용해서 데이터를 별도로 정제해줘야 한다.
(2) KCI에서 메타데이터 다운로드 받기
KCI는 자체 기능으로 원하는 논문에 대한 서지 메타데이터를 제공한다. 직접 KCI에서 데이터를 제공하는 만큼, 크롤링한 데이터보다 훨씬 품질이 좋다. 아래 그림에서 '엑셀' 버튼을 클릭하면, 약 19개의 메타데이터를 포함한 논문 데이터를 얻을 수 있다. 하지만 이 엑셀 다운로드는 초록을 제공하지 않는다. 초록 데이터까지 얻고 싶다면, '서지정보 내보내기' 버튼으로 초록 데이터까지 얻을 수 있다.

(3) KCI 크롤링하기
파이썬의 requests와 beautifulsoup 라이브러리를 활용해 간단하게 크롤링을 할 수 있다. 다음 방법은 앞서 엑셀로 다운로드 받은 KCI 논문의 개별 페이지에서 추가적으로 얻고 싶은 데이터를 크롤링하는 코드다. df로 불러온 데이터는 앞서 다운로드 받은 엑셀 데이터다. 간혹 초록 데이터가 없는 경우는 에러가 떠서 try와 except 구문으로 처리해주면 된다.
import requests
from bs4 import BeautifulSoup
from tqdm import tqdm
df['초록'] = ""
url = "https://www.kci.go.kr/kciportal/ci/sereArticleSearch/ciSereArtiView.kci?sereArticleSearchBean.artiId="
for idx, row in tqdm(df.iterrows(), total = df.shape[0]):
# 현재 진행중인 논문ID
print("\n논문ID: ", row['논문ID'])
response = requests.get(url + row['논문ID'])
content = response.content
soup = BeautifulSoup(content, 'lxml')
try:
abs = soup.find('p', id='korAbst').text.strip()
df.at[idx, '초록'] = abs
print(abs)
# 추출이 안되면 빈칸으로 처리
except Exception as e:
print(f"초록 추출 오류: {e}")
df.at[idx, '초록'] = ""
혹시 파이썬에 익숙하지 않은 사람이라면, 이 코드를 복사해서 ChatGPT나 Gemini에게 설명해달라고 해보자. 한 줄씩 잘 설명해 줄 것이고, 추가로 다른 데이터를 크롤링하는 방법까지 물어본다면 유용하게 사용할 수 있을 것이다.
추가: 텍스톰을 쓰지 말아야 하는 이유
앞서 언급한 방법 외에 텍스톰이란 솔루션을 사용하는 방법도 있다. 수업시간에 사용한 거라 테스트는 해봤지만, 데이터의 신뢰도 측면에서 논문의 연구방법으로 사용하기 어렵다는 판단을 하고 있다. 적어도 텍스톰을 텍스트 분석의 방법으로 사용할 것이라면, 어떤 한계를 갖고 있는지 생각해보는 것이 좋다.
아래 그림은 텍스톰에서 '디지털 아카이브'에 대해 1년간의 학술논문을 수집한 결과다. 심지어 '제목+본문'으로 중복을 제거한 결과이기도 하다. 텍스톰은 최대 1,000건의 데이터 수집만 가능하지만, 아래와 같이 매우! 중복이 많다. 크롤링하는 과정에서 상당히 많은 중복 데이터를 가져오는데, 텍스톰에 내장된 정제 기능으로 중복이 잘 제거되지 않는다. 또한, 텍스톰이 가져오는 네이버학술정보의 한계로 보이는데, 본문에 해당하는 내용이 명확하지 않다. 어떤 논문은 초록에 대한 정보를, 다른 논문은 키워드를, 또 다른 논문은 목차를 담고 있어서 어떤 것을 기준으로 텍스트 분석했는지 알 수 없다. 실제로 이 데이터를 가지고 파이썬으로 중복을 제거하니 1000건에서 208건으로 줄었다...🥲

또 다른 단점은 토큰의 개수가 많다면 현저하게 데이터 분석 성능이 구려진다는 것이다. 중복이 제거되지 않은 1,000건의 논문을 형태소 분석한다면, 약 1.9만개의 토큰이 생성된다(단순한 명사 추출 기준). 이 때, 불용어를 제거하거나 사용자 단어를 설정하기 위해 다시 정제를 한다면... 1시간 이상의 시간이 소요된다. 즉, 아주 어중간한 텍스트 양이 아니라면 텍스톰으로 돌리긴 어렵다.
그럼에도 불구하고 코딩을 할 줄 몰라서... 텍스톰을 써야 하는 방법 밖에 없다고 생각한다면, 코딩을 할 수 있는 사람에게 외주를 주거나 ChatGPT나 Gemini를 활용할 수 있다. 아니면 엑셀로도 전처리가 가능하니 분석만 텍스톰으로 하는 방법도 존재한다.
최근에 크롬 익스텐션인 Easy Scraper라는 크롤링 도구를 알게됐다. 테스트 해볼 겸 수업시간의 과제에 활용해보았다. 텍스트 분석을 위해 논문의 서지 메타데이터를 수집해야 했는데, 간단하게 수집한 방법을 설명한다. 추가적으로 텍스톰으로 수집하거나 정제한 데이터의 한계를 설명한다.
데이터 수집 출처
논문의 서지데이터는 2가지의 출처를 활용했다. 첫째, DBpia의 검색 결과를 크롤링한다. DBpia는 논문의 메타데이터에 대해 다운로드 기능을 제공하지 않아서 Easy Scraper로 크롤링한다. 둘째, KCI에서 서지 메타데이터를 다운로드 받는다. KCI는 키워드 검색한 결과에 해당하는 논문의 서지사항을 엑셀로 다운로드 받을 수 있다. 약 19개의 메타데이터(예: 제목, URL, 저자, 학술지명)를 제공하지만, 초록은 제공하지 않는다.
Easy Scraper 설치
크롬 웹 스토어에서 Easy Scraper를 다운로드 받으면 된다. 설치 이후 크롬 브라우저 상단의 툴바에서 Easy Scraper를 확인할 수 있다.
(1) DBpia에서 메타데이터 크롤링하기
DBpia에서 원하는 키워드를 검색한 후, 해당 페이지에서 Easy Scraper를 클릭하면 다음과 같은 창이 나타난다. (아마) html의 li 또는 table을 인식하기 때문에 본인이 의도하지 않는 구역으로 크롤링될 수 있다. 그럴 때는 크롤링된 표 위에 있는 Change List 버튼을 클릭하고, 크롤링하고 싶은 구역을 선택하면 된다(크롤링 영역이 노란색으로 변한다). 페이지별로 크롤링을 하고 싶다면, Action to load items 아래의 토글 버튼에서 'click link to navigate to next page'를 선택한다. 파란색 Select 버튼을 누르고, 다음 페이지에 해당하는 버튼을 클릭한 다음 Start Scraping 버튼을 클릭하면 된다(페이지가 끝날 때까지 같은 것을 반복한다). 크롤링이 끝났다면 표 상단의 CSV 또는 JSON 버튼을 클릭해 데이터를 다운받는다.
다만, 이렇게 다운로드 받은 데이터는 웹 페이지에 표시된 것을 그대로 긁은 것이기 때문에 상당한 정제가 필요하다. 엑셀이나 파이썬 등을 사용해서 데이터를 별도로 정제해줘야 한다.
(2) KCI에서 메타데이터 다운로드 받기
KCI는 자체 기능으로 원하는 논문에 대한 서지 메타데이터를 제공한다. 직접 KCI에서 데이터를 제공하는 만큼, 크롤링한 데이터보다 훨씬 품질이 좋다. 아래 그림에서 '엑셀' 버튼을 클릭하면, 약 19개의 메타데이터를 포함한 논문 데이터를 얻을 수 있다. 하지만 이 엑셀 다운로드는 초록을 제공하지 않는다. 초록 데이터까지 얻고 싶다면, '서지정보 내보내기' 버튼으로 초록 데이터까지 얻을 수 있다.
(3) KCI 크롤링하기
파이썬의 requests와 beautifulsoup 라이브러리를 활용해 간단하게 크롤링을 할 수 있다. 다음 방법은 앞서 엑셀로 다운로드 받은 KCI 논문의 개별 페이지에서 추가적으로 얻고 싶은 데이터를 크롤링하는 코드다. df로 불러온 데이터는 앞서 다운로드 받은 엑셀 데이터다. 간혹 초록 데이터가 없는 경우는 에러가 떠서 try와 except 구문으로 처리해주면 된다.
import requests
from bs4 import BeautifulSoup
from tqdm import tqdm
df['초록'] = ""
url = "https://www.kci.go.kr/kciportal/ci/sereArticleSearch/ciSereArtiView.kci?sereArticleSearchBean.artiId="
for idx, row in tqdm(df.iterrows(), total = df.shape[0]):
# 현재 진행중인 논문ID
print("\n논문ID: ", row['논문ID'])
response = requests.get(url + row['논문ID'])
content = response.content
soup = BeautifulSoup(content, 'lxml')
try:
abs = soup.find('p', id='korAbst').text.strip()
df.at[idx, '초록'] = abs
print(abs)
# 추출이 안되면 빈칸으로 처리
except Exception as e:
print(f"초록 추출 오류: {e}")
df.at[idx, '초록'] = ""
혹시 파이썬에 익숙하지 않은 사람이라면, 이 코드를 복사해서 ChatGPT나 Gemini에게 설명해달라고 해보자. 한 줄씩 잘 설명해 줄 것이고, 추가로 다른 데이터를 크롤링하는 방법까지 물어본다면 유용하게 사용할 수 있을 것이다.
추가: 텍스톰을 쓰지 말아야 하는 이유
앞서 언급한 방법 외에 텍스톰이란 솔루션을 사용하는 방법도 있다. 수업시간에 사용한 거라 테스트는 해봤지만, 데이터의 신뢰도 측면에서 논문의 연구방법으로 사용하기 어렵다는 판단을 하고 있다. 적어도 텍스톰을 텍스트 분석의 방법으로 사용할 것이라면, 어떤 한계를 갖고 있는지 생각해보는 것이 좋다.
아래 그림은 텍스톰에서 '디지털 아카이브'에 대해 1년간의 학술논문을 수집한 결과다. 심지어 '제목+본문'으로 중복을 제거한 결과이기도 하다. 텍스톰은 최대 1,000건의 데이터 수집만 가능하지만, 아래와 같이 매우! 중복이 많다. 크롤링하는 과정에서 상당히 많은 중복 데이터를 가져오는데, 텍스톰에 내장된 정제 기능으로 중복이 잘 제거되지 않는다. 또한, 텍스톰이 가져오는 네이버학술정보의 한계로 보이는데, 본문에 해당하는 내용이 명확하지 않다. 어떤 논문은 초록에 대한 정보를, 다른 논문은 키워드를, 또 다른 논문은 목차를 담고 있어서 어떤 것을 기준으로 텍스트 분석했는지 알 수 없다. 실제로 이 데이터를 가지고 파이썬으로 중복을 제거하니 1000건에서 208건으로 줄었다...🥲
또 다른 단점은 토큰의 개수가 많다면 현저하게 데이터 분석 성능이 구려진다는 것이다. 중복이 제거되지 않은 1,000건의 논문을 형태소 분석한다면, 약 1.9만개의 토큰이 생성된다(단순한 명사 추출 기준). 이 때, 불용어를 제거하거나 사용자 단어를 설정하기 위해 다시 정제를 한다면... 1시간 이상의 시간이 소요된다. 즉, 아주 어중간한 텍스트 양이 아니라면 텍스톰으로 돌리긴 어렵다.
그럼에도 불구하고 코딩을 할 줄 몰라서... 텍스톰을 써야 하는 방법 밖에 없다고 생각한다면, 코딩을 할 수 있는 사람에게 외주를 주거나 ChatGPT나 Gemini를 활용할 수 있다. 아니면 엑셀로도 전처리가 가능하니 분석만 텍스톰으로 하는 방법도 존재한다.