Blazegraph에 대용량 데이터 넣기 (feat. fastload.properties)
2023. 11. 27. by 박하람
작은 트리플 데이터는 단순히 UI 상에서 조작해서 넣을 수 있지만, 트리플 데이터의 규모가 억 단위로 넘어가면 수동으로 데이터를 넣기 어렵다.
대부분의 트리플 스토어는 bulk data를 업로드하는 기능을 지원하고 있다. 오늘 포스팅에서 다룰 데이터베이스는 blazegraph로 대용량 데이터를 넣는 방법이다.
블레이즈그래프에 대용량 데이터를 넣는 것은 이제 익숙하긴 하지만, 오랜만에 할 때마다 가끔씩 어떻게 했더라... 하는 바람에 기록으로 남겨둔다!
오늘 포스팅은 솜솜의 [blazegraph] blazegraph 설치와 대용량 데이터 넣기를 따라하면서 이슈사항을 기록했다.
Blazegraph 설치와 실행
블레이즈그래프의 깃헙에서 Blazegraph의 최신 버전을 다운로드한다. 내가 설치한 Blazegraph 버전은 Blazegraph 2.1.6 Release Candidate이다. 보통은 blazegraph.jar 파일을 다운로드 받는데, bigdata.jar 파일을 다운로드 받아도 된다. 둘 다 사용해봤는데, 둘의 큰 차이는 없고 이름만 다르다고 생각한다. (원래 이름이 bigdata 였다가 blazegraph로 바뀌어서 그렇다는 스토리가 있다)
실행 방법은 blazegraph를 다운로드 받은 폴더에 들어가서 다음의 코드를 실행한다. 만약 메모리 사이즈를 늘리고 싶다면, -Xmx8g, -Xmx16g 등으로 수정할 수 있다. blazegraph가 실행되면, blazegraph.jar가 있는 폴더에 blazegraph.jnl 파일이 생성된다.
java -server -Xmx4g -jar blazegraph.jar
fastload.properties 추가
blazegraph에 대용량 데이터를 넣으려면, fastload.properties 파일을 추가해줘야 한다. 반드시 blazegraph.jar와 동일한 위치에 두어야 한다.
# blazegraph가 있는 위치로 이동
cd folder
# fastload.properties 생성
vim fastload.properties
아래 코드는 blazegraph에서 제공하는 fastload.properties 예시다. 특별히 바꾸지 않아도 bulk data 업로드는 잘 작동한다. 주의할 점은 빠르게 넣기 위해 textIndex 기능을 해제하고 있다는 것이다. 이후 빠른 쿼리를 위해 textIndex를 rebuild 해주는 게 필요하다.
# This configuration turns off incremental inference for load and retract, so
# you must explicitly force these operations if you want to compute the closure
# of the knowledge base. Forcing the closure requires punching through the SAIL
# layer. Of course, if you are not using inference then this configuration is
# just the ticket and is quite fast.
# set the initial and maximum extent of the journal
com.bigdata.journal.AbstractJournal.initialExtent=209715200
com.bigdata.journal.AbstractJournal.maximumExtent=209715200
com.bigdata.journal.AbstractJournal.file=blazegraph.jnl
# turn off automatic inference in the SAIL
com.bigdata.rdf.sail.truthMaintenance=false
# don't store justification chains, meaning retraction requires full manual
# re-closure of the database
com.bigdata.rdf.store.AbstractTripleStore.justify=false
# turn off the statement identifiers feature for provenance
com.bigdata.rdf.store.AbstractTripleStore.statementIdentifiers=false
# turn off the free text index
com.bigdata.rdf.store.AbstractTripleStore.textIndex=false
# RWStore (scalable single machine backend)
com.bigdata.journal.AbstractJournal.bufferMode=DiskRW
fastload.properties 실행
솜솜의 포스팅에서 언급한 것처럼 blazegraph를 종료해야 실행된다. blazegraph는 기본적으로 kb라는 네임스페이스가 설정되어 있다. kb는 quad 데이터를 넣게 설정되어 있다. kb 네임스페이스에 트리플 데이터를 넣는다면, 데이터 형식 오류로 bulk data 업로드가 작동하지 않는다. 트리플 데이터는 quad 설정 없이 namespace를 추가해줘야 한다. Mode가 triple 모드인지 확인하자.
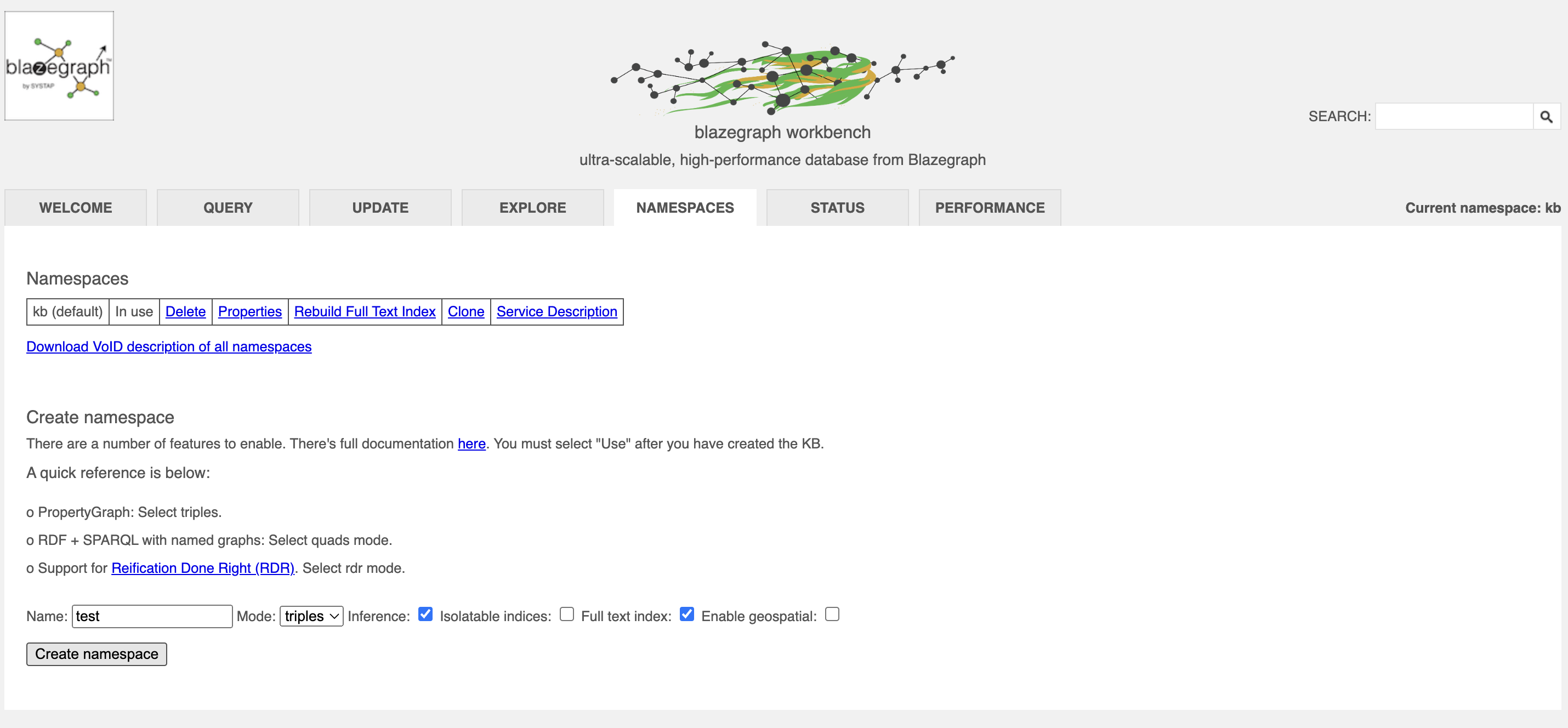
fastload.properties가 생성되었다면 다음의 코드를 입력한다. -namespace 다음은 데이터를 넣으려는 네임스페이스 이름을 작성해야 하고, fastload.properties 다음은 업로드하고 싶은 데이터가 담긴 폴더 경로를 입력한다.
java -cp blazegraph.jar com.bigdata.rdf.store.DataLoader -namespace test fastload.properties /Users/harampark/Documents/folder
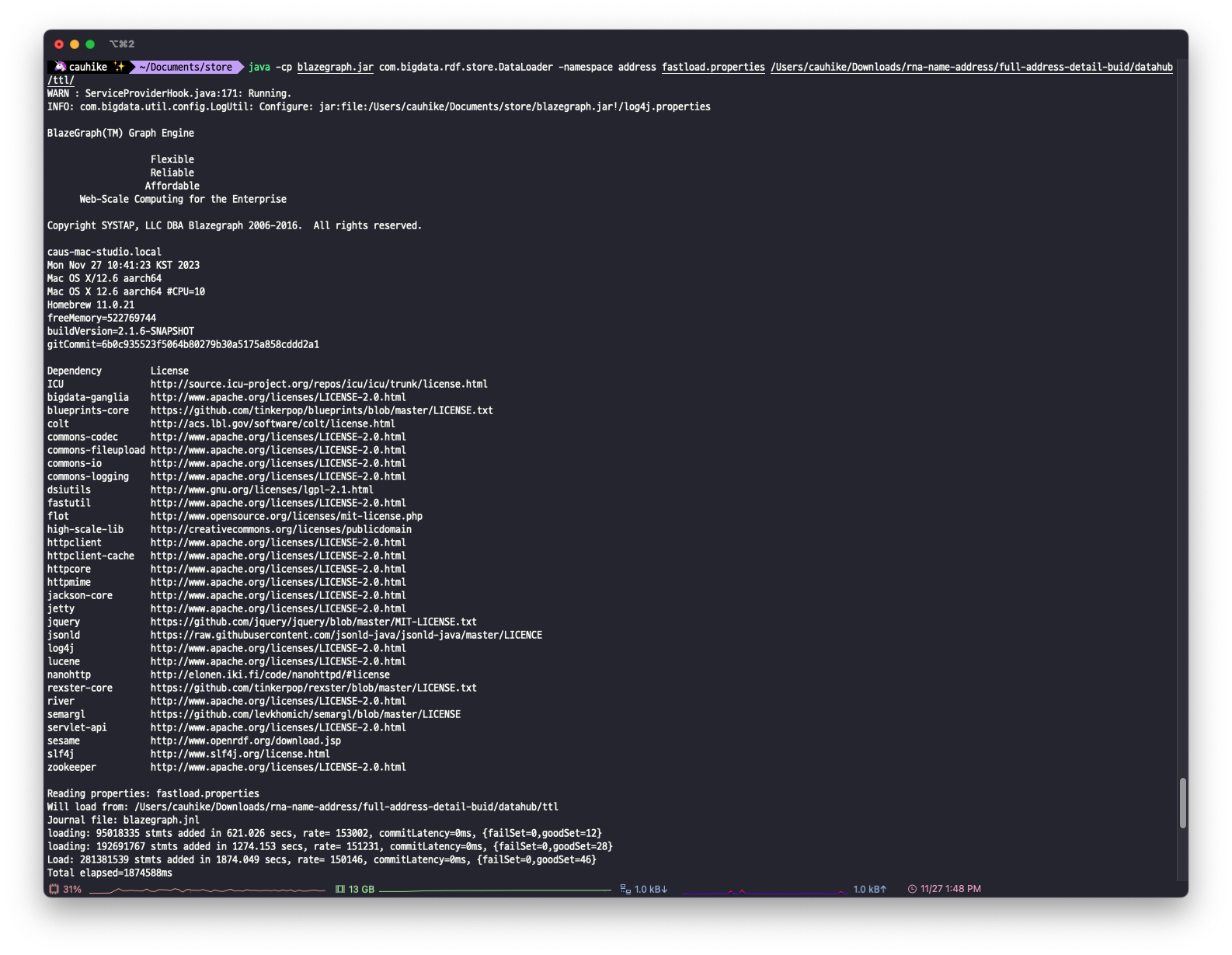
실행 결과가 다음과 같이 작동된다면, 정상적으로 실행되고 있다! 초기에 Journal file: blazegraph.jnl만 뜨고, 나머지는 뜨지 않는다. 트리플 데이터가 무사히 들어가면 트리플의 개수와 성공한 파일 개수 (goodSet)이 뜬다. blazegraph를 작동한 머신의 성능은 메모리 32GB, 용량이 500GB이다. 약 2억 8천개의 트리플 데이터가 약 30분만에 blazegraph에 저장된 것을 확인할 수 있다.
추가: blazegraph 이동 또는 복사하기
blazegraph의 이동은 매우 쉽다. blazegraph.jar와 blazegraph.jnl, rules.log가 있는 폴더를 모두 복사하면 된다. 데이터가 업로드되면, blazegraph.jnl 파일의 용량이 매우 커진다. 충분한 용량이 있는 머신을 사용하는 게 중요하다.
추가: named graph로 대용량 데이터 업로드하기
named graph로 데이터를 넣을 수 있는 방식은 찾았지만 (이전 포스팅 참고: Blazegraph에 named graph 업로드하기), quad 형식에 맞게 데이터를 만들어줘야 한다. 즉, s-p-o 구조가 아니라 s-p-o-q 구조로 생성해야 한다. q는 named graph URI가 작성된다. 하지만, quad 데이터는 named graph URI가 추가되기 때문에 데이터의 용량이 더욱 커진다..🥲 named graph가 꼭 필요하다면 quad 데이터로 만들겠지만, 데이터 자체를 quad 형식으로 만들어야 하기 때문에 계륵 같은 기능 같다.
작은 트리플 데이터는 단순히 UI 상에서 조작해서 넣을 수 있지만, 트리플 데이터의 규모가 억 단위로 넘어가면 수동으로 데이터를 넣기 어렵다.
대부분의 트리플 스토어는 bulk data를 업로드하는 기능을 지원하고 있다. 오늘 포스팅에서 다룰 데이터베이스는 blazegraph로 대용량 데이터를 넣는 방법이다.
블레이즈그래프에 대용량 데이터를 넣는 것은 이제 익숙하긴 하지만, 오랜만에 할 때마다 가끔씩 어떻게 했더라... 하는 바람에 기록으로 남겨둔다!
오늘 포스팅은 솜솜의 [blazegraph] blazegraph 설치와 대용량 데이터 넣기를 따라하면서 이슈사항을 기록했다.
Blazegraph 설치와 실행
블레이즈그래프의 깃헙에서 Blazegraph의 최신 버전을 다운로드한다. 내가 설치한 Blazegraph 버전은 Blazegraph 2.1.6 Release Candidate이다. 보통은 blazegraph.jar 파일을 다운로드 받는데, bigdata.jar 파일을 다운로드 받아도 된다. 둘 다 사용해봤는데, 둘의 큰 차이는 없고 이름만 다르다고 생각한다. (원래 이름이 bigdata 였다가 blazegraph로 바뀌어서 그렇다는 스토리가 있다)
실행 방법은 blazegraph를 다운로드 받은 폴더에 들어가서 다음의 코드를 실행한다. 만약 메모리 사이즈를 늘리고 싶다면, -Xmx8g, -Xmx16g 등으로 수정할 수 있다. blazegraph가 실행되면, blazegraph.jar가 있는 폴더에 blazegraph.jnl 파일이 생성된다.
java -server -Xmx4g -jar blazegraph.jar
fastload.properties 추가
blazegraph에 대용량 데이터를 넣으려면, fastload.properties 파일을 추가해줘야 한다. 반드시 blazegraph.jar와 동일한 위치에 두어야 한다.
# blazegraph가 있는 위치로 이동
cd folder
# fastload.properties 생성
vim fastload.properties
아래 코드는 blazegraph에서 제공하는 fastload.properties 예시다. 특별히 바꾸지 않아도 bulk data 업로드는 잘 작동한다. 주의할 점은 빠르게 넣기 위해 textIndex 기능을 해제하고 있다는 것이다. 이후 빠른 쿼리를 위해 textIndex를 rebuild 해주는 게 필요하다.
# This configuration turns off incremental inference for load and retract, so
# you must explicitly force these operations if you want to compute the closure
# of the knowledge base. Forcing the closure requires punching through the SAIL
# layer. Of course, if you are not using inference then this configuration is
# just the ticket and is quite fast.
# set the initial and maximum extent of the journal
com.bigdata.journal.AbstractJournal.initialExtent=209715200
com.bigdata.journal.AbstractJournal.maximumExtent=209715200
com.bigdata.journal.AbstractJournal.file=blazegraph.jnl
# turn off automatic inference in the SAIL
com.bigdata.rdf.sail.truthMaintenance=false
# don't store justification chains, meaning retraction requires full manual
# re-closure of the database
com.bigdata.rdf.store.AbstractTripleStore.justify=false
# turn off the statement identifiers feature for provenance
com.bigdata.rdf.store.AbstractTripleStore.statementIdentifiers=false
# turn off the free text index
com.bigdata.rdf.store.AbstractTripleStore.textIndex=false
# RWStore (scalable single machine backend)
com.bigdata.journal.AbstractJournal.bufferMode=DiskRW
fastload.properties 실행
솜솜의 포스팅에서 언급한 것처럼 blazegraph를 종료해야 실행된다. blazegraph는 기본적으로 kb라는 네임스페이스가 설정되어 있다. kb는 quad 데이터를 넣게 설정되어 있다. kb 네임스페이스에 트리플 데이터를 넣는다면, 데이터 형식 오류로 bulk data 업로드가 작동하지 않는다. 트리플 데이터는 quad 설정 없이 namespace를 추가해줘야 한다. Mode가 triple 모드인지 확인하자.
fastload.properties가 생성되었다면 다음의 코드를 입력한다. -namespace 다음은 데이터를 넣으려는 네임스페이스 이름을 작성해야 하고, fastload.properties 다음은 업로드하고 싶은 데이터가 담긴 폴더 경로를 입력한다.
java -cp blazegraph.jar com.bigdata.rdf.store.DataLoader -namespace test fastload.properties /Users/harampark/Documents/folder
실행 결과가 다음과 같이 작동된다면, 정상적으로 실행되고 있다! 초기에 Journal file: blazegraph.jnl만 뜨고, 나머지는 뜨지 않는다. 트리플 데이터가 무사히 들어가면 트리플의 개수와 성공한 파일 개수 (goodSet)이 뜬다. blazegraph를 작동한 머신의 성능은 메모리 32GB, 용량이 500GB이다. 약 2억 8천개의 트리플 데이터가 약 30분만에 blazegraph에 저장된 것을 확인할 수 있다.
추가: blazegraph 이동 또는 복사하기
blazegraph의 이동은 매우 쉽다. blazegraph.jar와 blazegraph.jnl, rules.log가 있는 폴더를 모두 복사하면 된다. 데이터가 업로드되면, blazegraph.jnl 파일의 용량이 매우 커진다. 충분한 용량이 있는 머신을 사용하는 게 중요하다.
추가: named graph로 대용량 데이터 업로드하기
named graph로 데이터를 넣을 수 있는 방식은 찾았지만 (이전 포스팅 참고: Blazegraph에 named graph 업로드하기), quad 형식에 맞게 데이터를 만들어줘야 한다. 즉, s-p-o 구조가 아니라 s-p-o-q 구조로 생성해야 한다. q는 named graph URI가 작성된다. 하지만, quad 데이터는 named graph URI가 추가되기 때문에 데이터의 용량이 더욱 커진다..🥲 named graph가 꼭 필요하다면 quad 데이터로 만들겠지만, 데이터 자체를 quad 형식으로 만들어야 하기 때문에 계륵 같은 기능 같다.